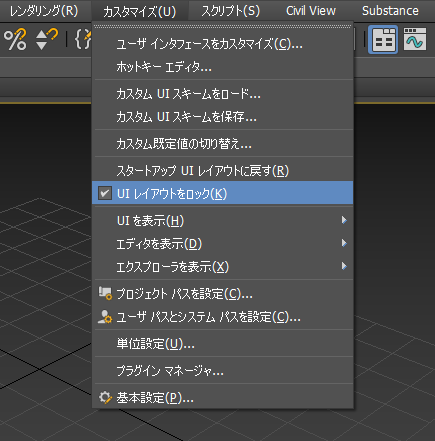
3ds Maxの「UIレイアウトをロック」について書いてみます。 3ds Maxは昔からフローティングウィンドウとドッキング可能なウィンドウが混在するソフトです。Max 2015のレイヤエクスプローラの変更くらいから、こ […]
Tips
3ds MaxのUIレイアウトをロック
![]()
3ds Maxの「UIレイアウトをロック」について書いてみます。 3ds Maxは昔からフローティングウィンドウとドッキング可能なウィンドウが混在するソフトです。Max 2015のレイヤエクスプローラの変更くらいから、こ […]
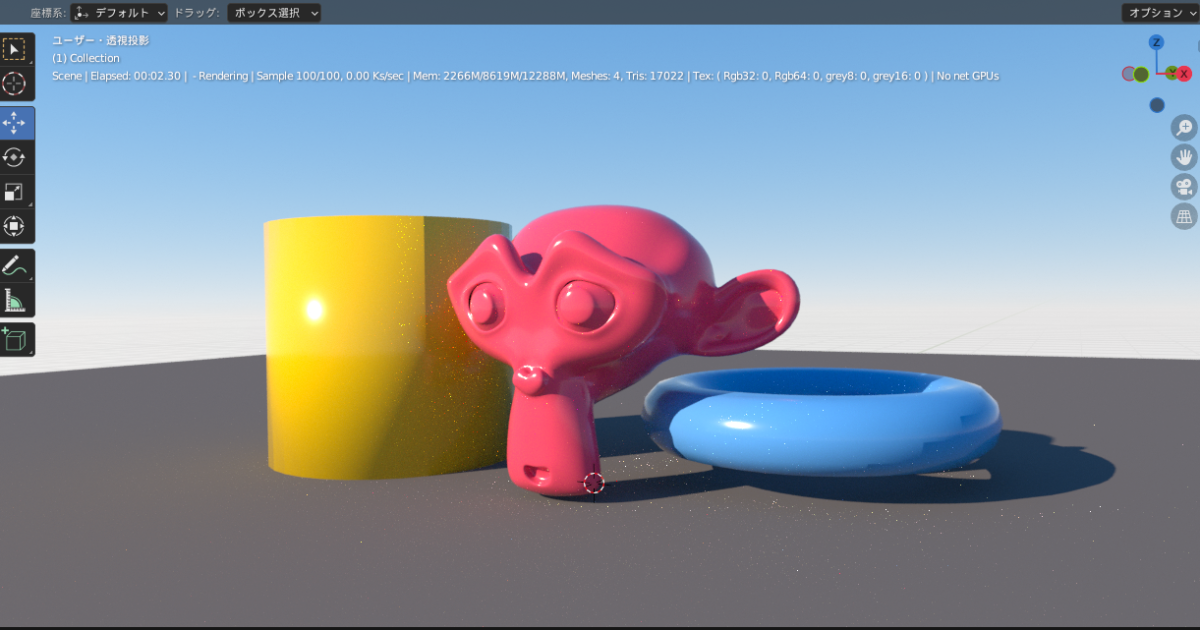
OctaneRender for Blenderのインストール方法のメモです。Blenderを少しさわれるようになったので、OctaneRenderがどんな風に公開されてるのかインストールしてみました。 O […]
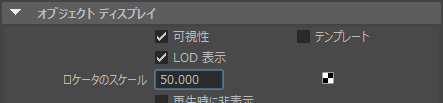
カメラやライトをMayaインポートしたとき、ビューポートでオブジェクトが小さくて見えないことがあります。そんな場合、選択したオブジェクトの「ロケータのスケール」を一括変更するMELスクリプトです。 { string $n […]
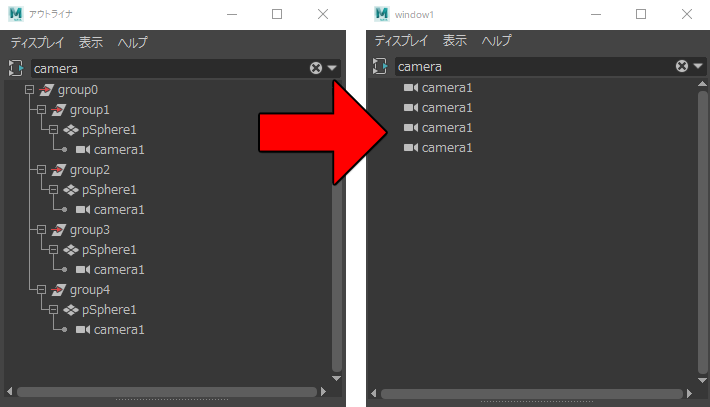
Mayaのアウトライナで、検索結果をフラット表示する方法について書いてみます。 Mayaのアウトライナでオブジェクトを検索して、検索したオブジェクトをまとめて選択したい場合があります。しかし、アウトライナの […]
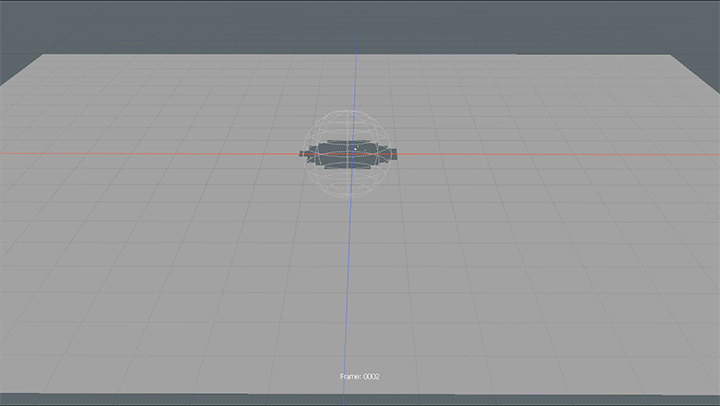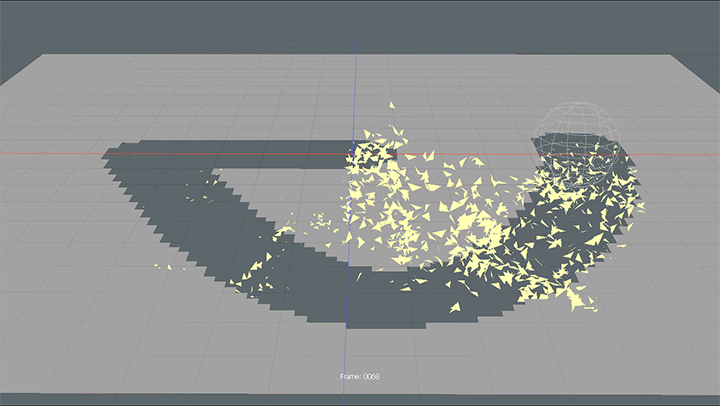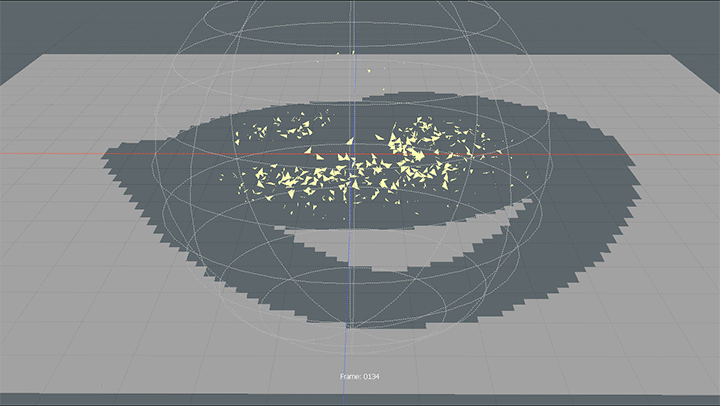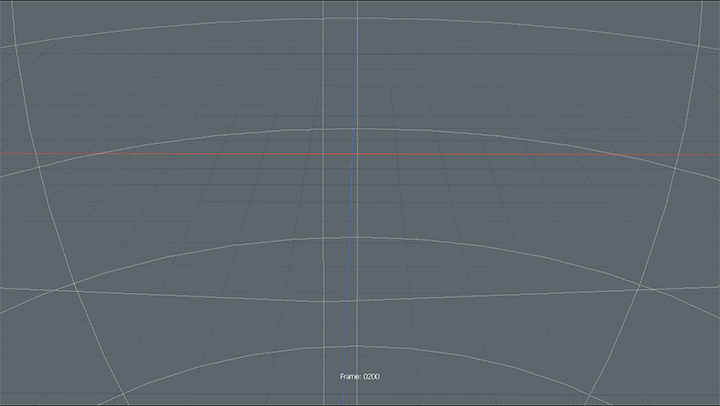
modoでポリゴンが消える表現について書いてみます。 TwitterでBlenderのジオメトリノードを使った作例が流れてきたので、同じような表現がmodoで作れるか軽くテストしてみました。 ちょっと無理やりな方法なので […]
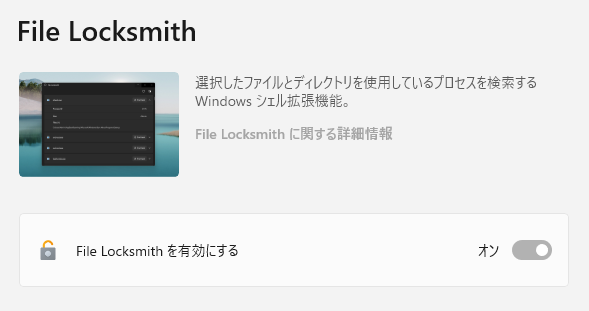
フォルダやファイルのロックを解除するソフト「File Locksmith」を紹介します。 Windowsでファイルを削除する場合に「別のプログラムがこのファイルを開いているので、操作を完了できません。」とメッセージが出て […]
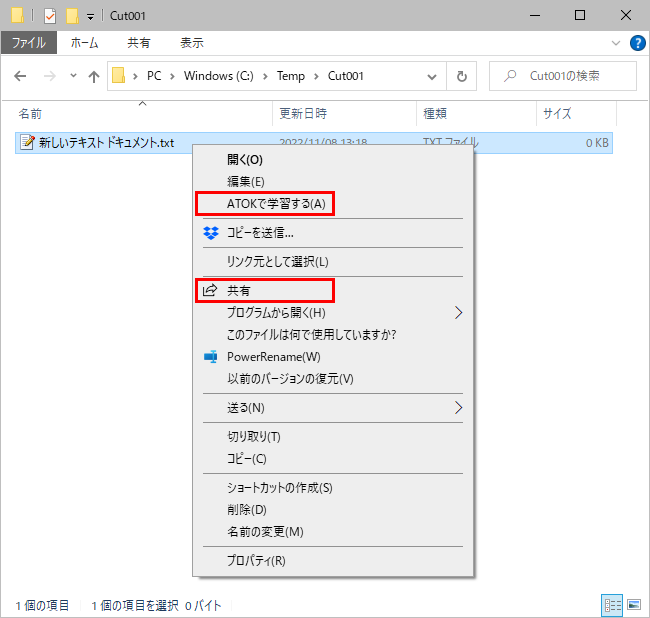
Windows 10 でコンテキストメニューを編集する方法について書いてみます。 Windowsではアプリケーションをインストールすると、コンテキストメニュー(右クリックメニュー)にアプリケーションのコマンドが勝手に追加 […]

サブディビジョンサーフェスを使用したエッジの処理によってスムージングにアーティファクトが出るという話を見かけたので、modoで検証してみました。三角ポリゴンを使用するとスムージングアーティファクトが目立たなくなるようです […]
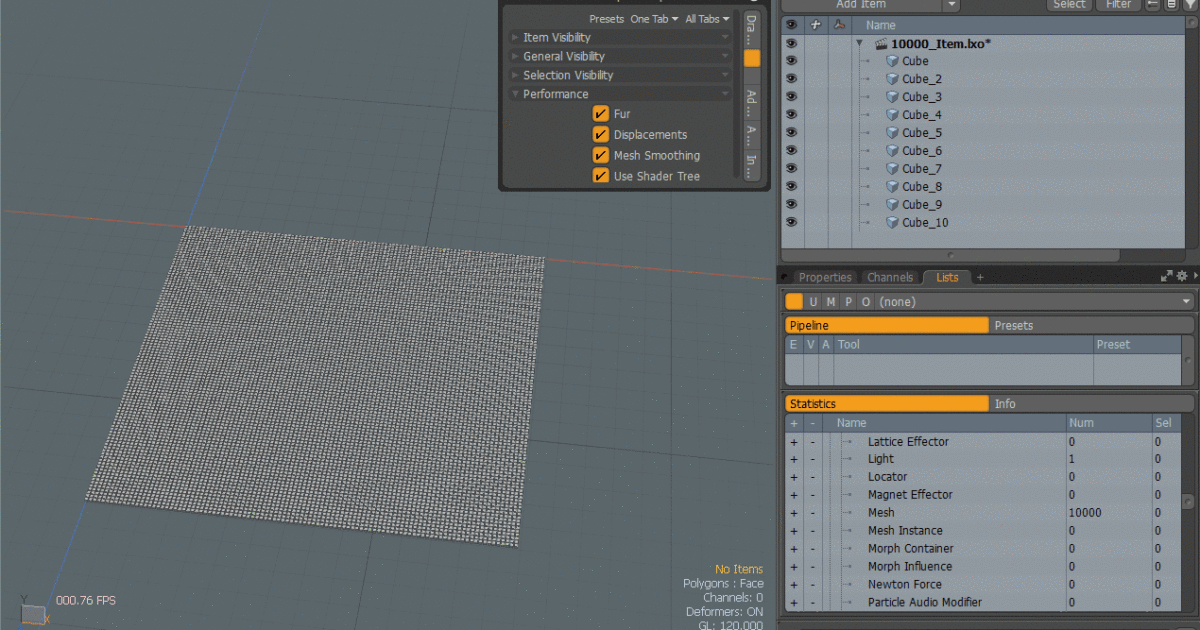
modoはアイテム数が多い場合にパフォーマンスが低下するという話題をよく見かけます。 ビューポートの表示を「デフォルト」以外に変更すると、速度が少し改善することに気がついたので記事に残しておきます。 ■サンプルファイル […]
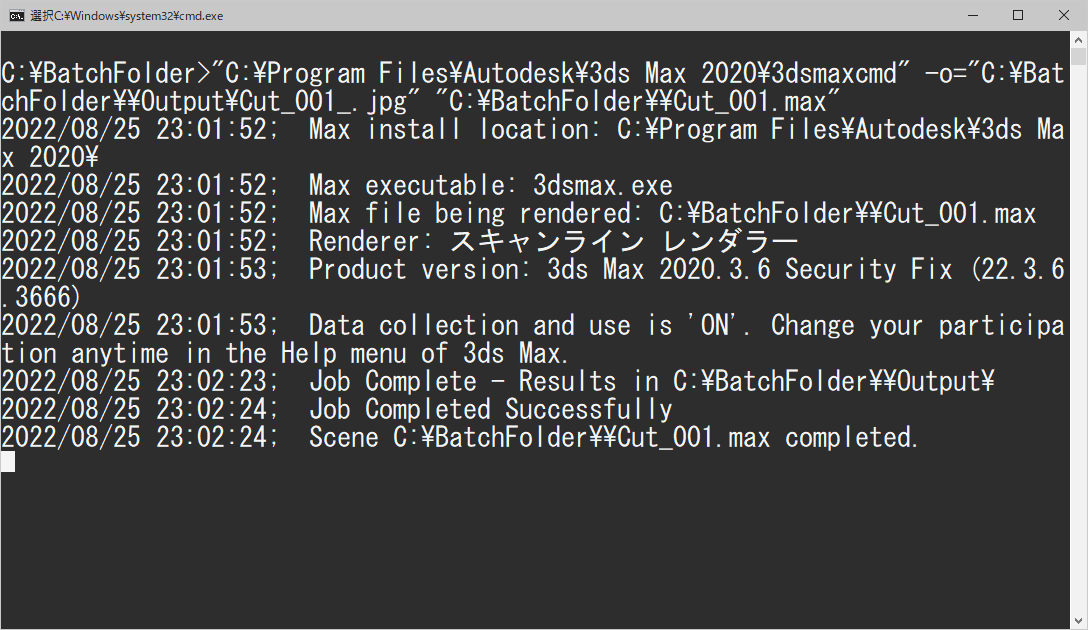
3dsMaxのコマンドライン(3dsmaxcmd.exe)を使用したバッチレンダリングの方法について書いてみます。 3dsMaxにはBackburnerやバッチ レンダリング ツールなどいくつかバッチレンダリング機能が搭 […]
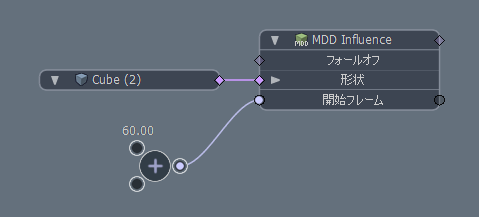
modoでMDDファイルを逆再生する方法について書いてみます。 modoには複数のアニメーションキャッシュ機能があります。 パーティクルキャッシュの場合はCSV Point CacheやRealflow Particle […]

modoでポリゴン面の広さに応じて、アイテムがスケールする表現の作り方について書いてみます。 ■サンプルファイル スケマティックはこんな感じです。 平面をAxis Drillで適当にスライスして、Polyg […]
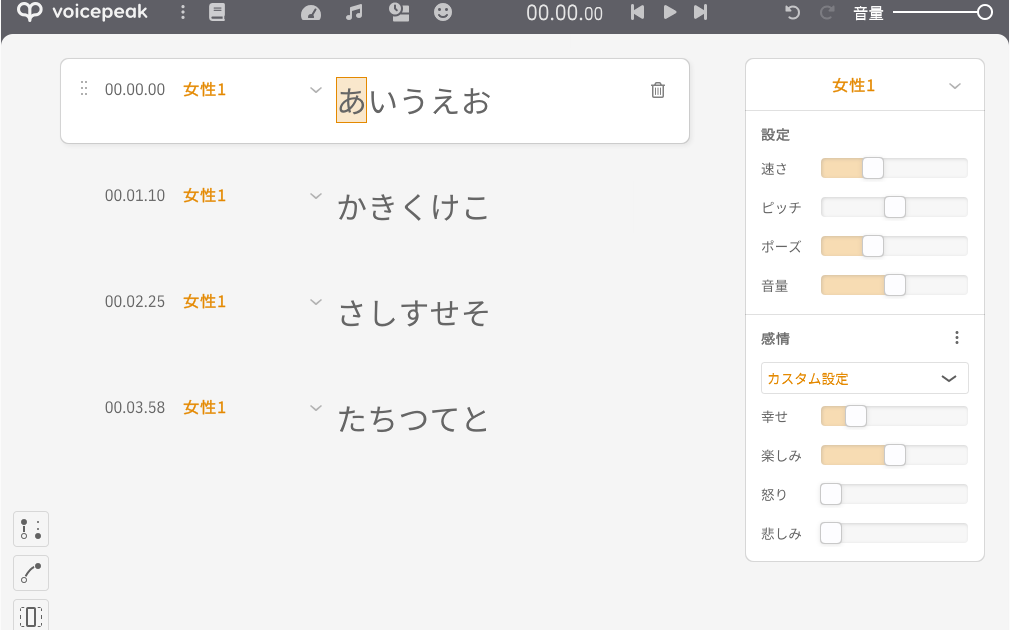
入力文字読み上げソフト「VOICEPEAK」で、セリフブロックの「ナレーター」や「感情」をまとて一括編集する方法について書いてみます。 VOICEPEAKはセリフブロックごとに「ナレーター」を設定したり、「感情」のパラメ […]

アイテムを重ならないように散布できるプラグイン「Discrete Particles」のメモです。使用バージョンは1.0です。 一部の設定を変更しないと機能が意図したように動作しなかったので、調べたこと残しておきます。 […]

modoでパーティクルにテクスチャを使用して色を設定する方法について書いてみたいと思います。 Steve Hillさんが公開していたビデオの内容を試してみた。という内容の記事です。 ■サンプルファイル &n […]