Nukeの機械学習機能「CopyCat」に関する記事が公開されています。CopyCatを使用すると人が手作業で行う作業を学習させて、作業を効率化できるようです。
https://www.fxguide.com/fxfeatured/copycat-inference-machine-learning-in-nuke/
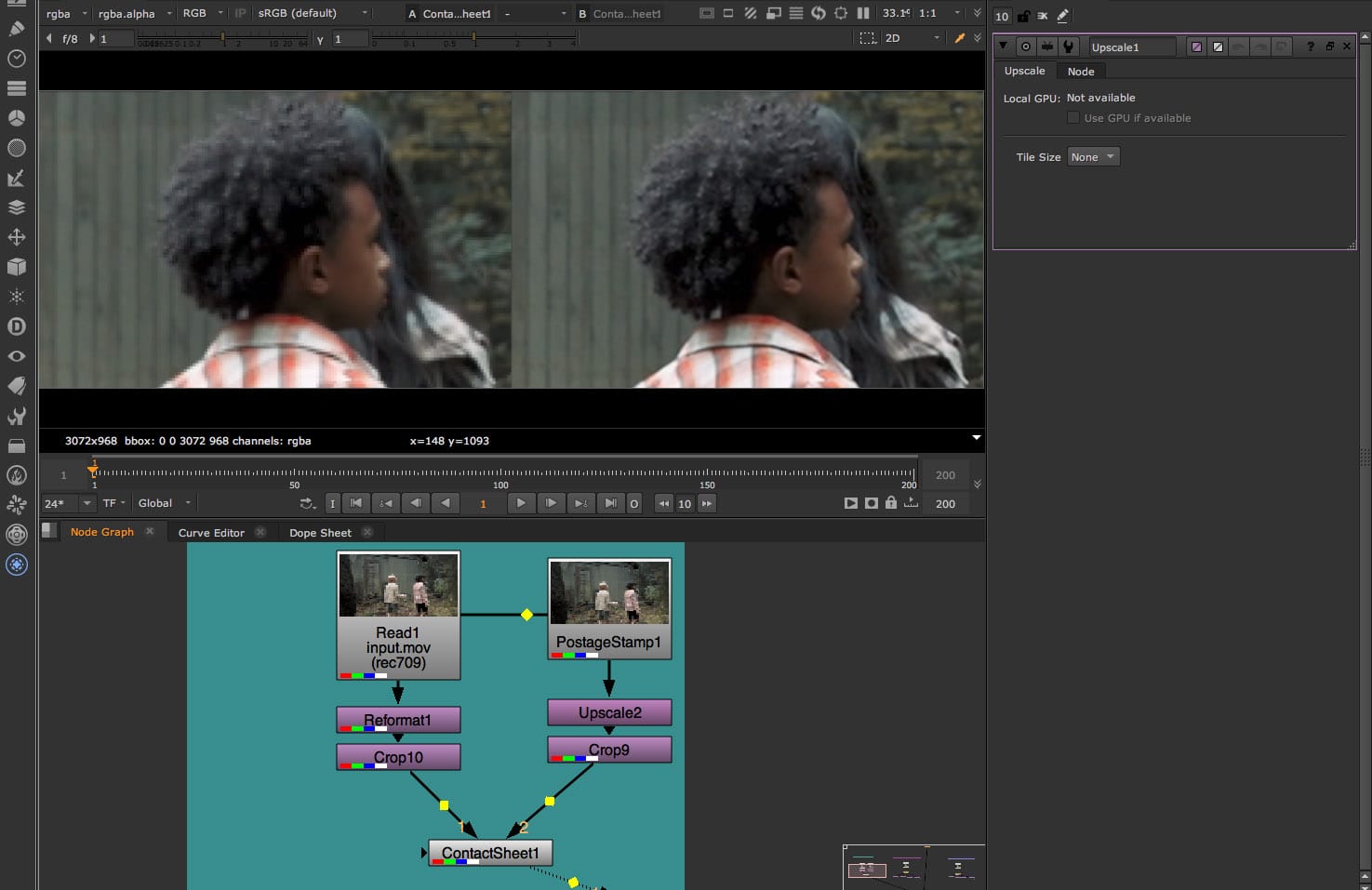
Nuke 13には、柔軟な機械学習ツールセットであるMachine Learning (ML)が含まれています。MLツールセットは、FoundryのA.I.Researchチーム(AIR)によって開発され、アップスケール、モーションブラー除去、トラッキングマーカー除去、ビューティーワーク、ガベージマットなどを含むツールセットのアプリケーションで、アーティストが特注エフェクトを作成できるようにしました。
MLツールセットの主な構成は以下の通りです
- CopyCat
アーティストは、シーケンス内の少数のフレームにエフェクトを作成し、CopyCatノードでこのエフェクトを再現するネットワークをトレーニングすることができます。このアーティストに焦点を当てたショット固有のアプローチにより、カスタムトレーニング環境、複雑なネットワーク権限、クラウドへのデータ送信なしに、Nuke内で比較的迅速に高品質なカスタムモデルを作成することができます。 - Inference
Copy Catによって生成されたニューラルネットワークを実行するノードで、モデルを画像シーケンスまたは別のシーケンスに適用します。 - UpscaleとDeblur
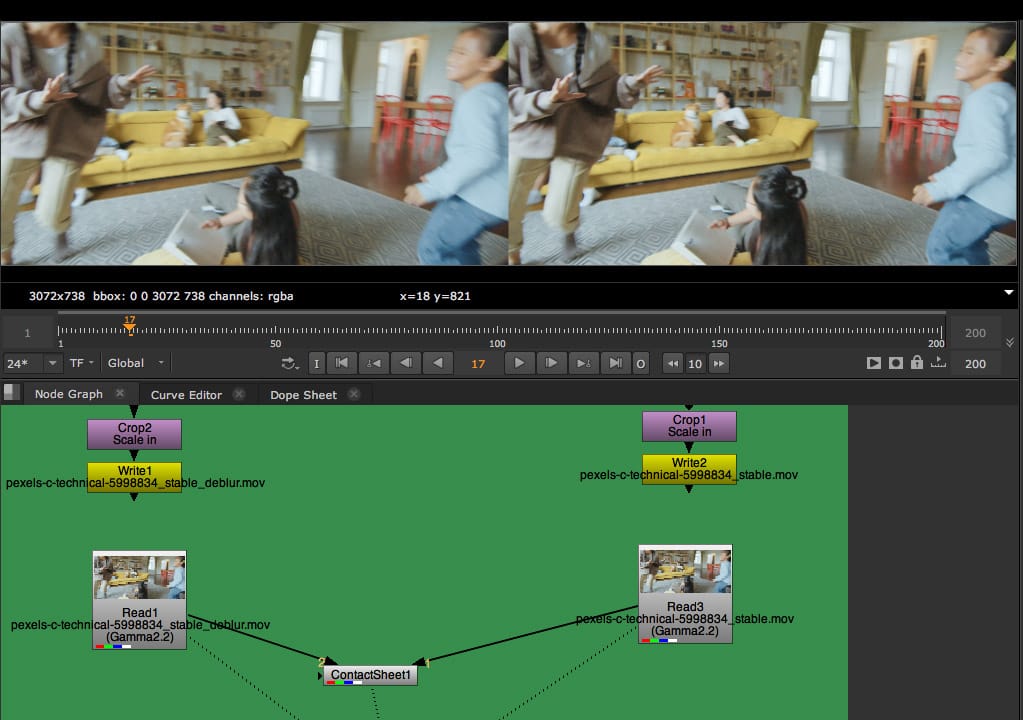
一般的な合成作業のための2つの新しいツールは、CopyCatとオープンソースのML-Serverの背後にあるML方法論を使用して開発されました。これらのノードのMLネットワークは、映像のリサイズやモーションブラーの除去といった主な用途に加え、CopyCatを使ってより高品質なショットやスタジオ固有のバージョンを作成するために改良することができます。
2年前、fxguideはNukeの中にMLツールを持ちながら並行して開発する方法を紹介する目的で、MLモデルの迅速なプロトタイピング、実験、開発を別のサーバー上で可能にするFoundryのオープンソースのクライアント/サーバーシステム、ML-Serverに関する記事を掲載しました。
Nuke v13で、ファウンドリーのAIRチームはNukeのネイティブノードを提供するようになりました。その中でも主要なものはCopyCatノードです。ML-Serverと同様に、MLツールの中核はMulti-Scale Recurrent Network (MSRN)です。「MSRNは魔法のようなネットワークで、様々な課題を解決し、それをうまく実現してくれます。MLがビジュアルエフェクトの問題解決に全く新しい世界をもたらすことは間違いありません。MLはNukeの新しいツールやノードではなく、問題を解決するための新しい方法であることが、とてもエキサイティングな点です。MLノードにトレーニング素材を提供し、その結果を推測するというアプローチは、まさに革命的であり、現在報道されている一般的なAIに関する誇大広告をも凌ぐものです。このようなAIツールがアーティストに取って代わることはないでしょうが、新世代の複雑なAIソリューションが展開される中で、AIツールを理解できない人たちは消えていくかもしれませんね。
教師あり学習
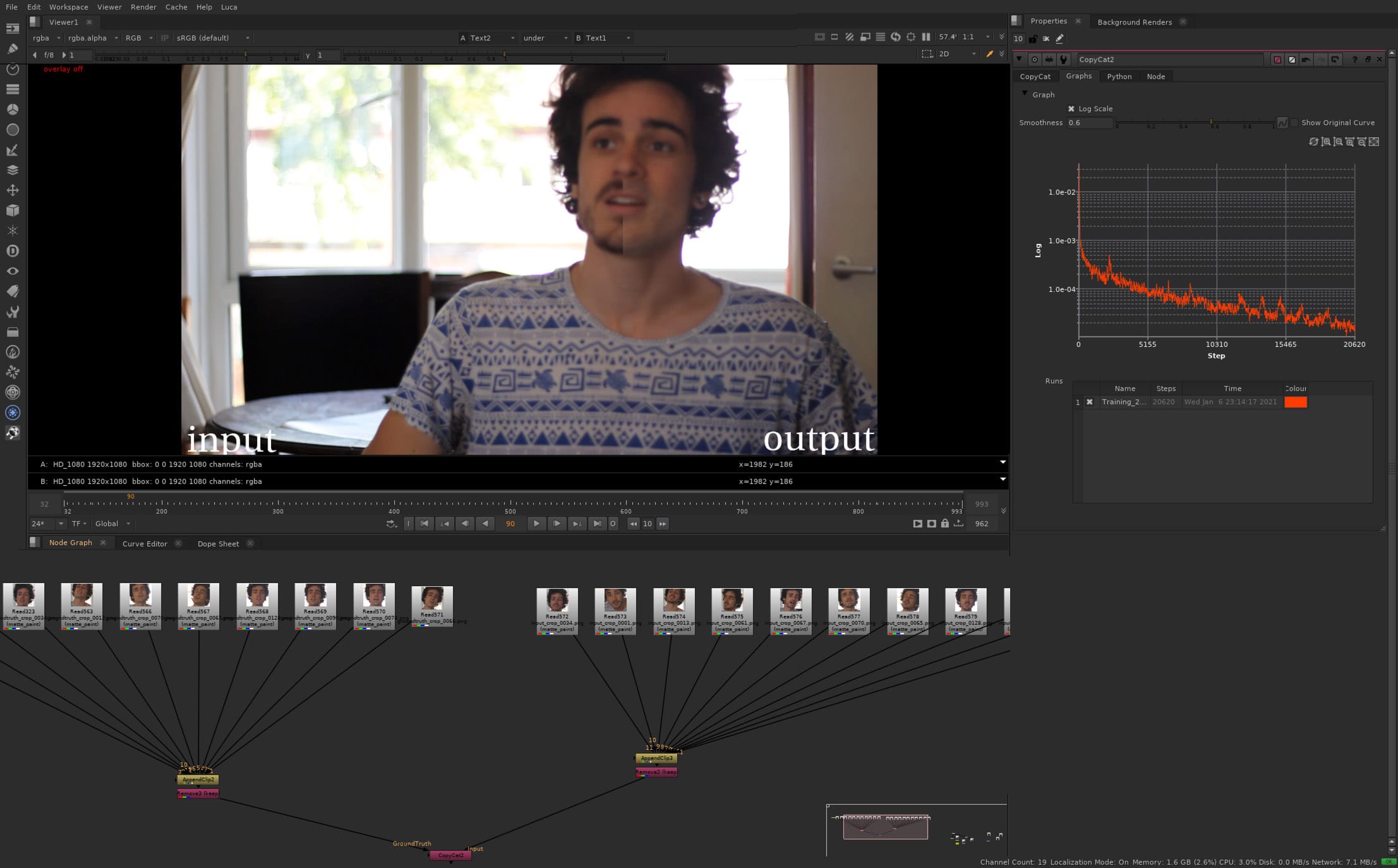
すべてのAIやMLが学習データの例を必要とするわけではありませんが、CopyCatノードは必要とします。これは、教師あり学習と呼ばれるMLの一種であるためです。重要なのは、教師なし学習や強化学習に分類されるMLソリューションもあるということです。
CopyCatの使い方は比較的簡単で、ロトやビューティーワークのサンプルフレームをNukeにビフォーアフターフレームとして提供します。すると、システムは何が行われたかを推測し、それをクリップに適用します。MLを本当に使いこなすには、この仕組みと、フードの下で実際に何が起こっているのかを理解することが大切です。動作を擬人化し、コンピューターが私たちと同じようにフレームを「見ている」と想像するのは簡単です。その出力はとても論理的で理にかなっているように見えるので、それがうまくいかないとき(そしてそれは間違いなく失敗する)、その失敗はほとんど意味をなさないように思えます。
まず理解すべきは、コンピュータは画像を理解していない、ということです。私たちは人や車をはっきりと見ていますが、コンピュータは決してそうではなく、ただピクセルを見て、出力が学習データと数学的に一致するようにエラーを減らそうとしているのです。コンピュータに学習データ空間の例から外れた推論を求めれば求めるほど、結果は悪くなります。コンピュータは、例から外挿することなく、空間の内側で最適な推論を行います。また、コンピュータはフレーム全体を1つのものとして見るのではなく、パッチ単位で作業を行います。
コンピュータが強力なのは、100万通りの方法を試し、より良い結果が得られれば、その推論を続けることができる点です。数学の用語で言えば、これはMLネットワークのエラーを減らすことに直結しています。このネットワークはレイヤーがあり、ディープネットワークと呼ばれています。エラーを減らすために、ニューラルネットワークの中のノードの重みを変えながら、そのアプローチに改良を加えていきます。このリップルバックをバックプロパゲーションと呼びます。誤差が大きい場合は、バックプロパゲーションによって誤差を小さくします。この誤差の減少をNukeでは視覚的にマッピングし、勾配降下と呼んでいます。人生のほとんどの事柄と同様に、道を間違えたり、「間違った木に吠える」ことは簡単です。数学の用語では、これはローカルミニマムが存在することを意味します。NukeにおけるCopyCatの最大の技術的偉業の1つは、AIRチームが、間違った方向やローカルミニマムを克服し、多くの異なる視覚的問題で勾配降下を効果的に駆動する一般的なツールを作り出したということです。FoundryがMulti-Scale Recurrent Networks(MSRN)を発明したわけではありませんが、AIRチームは、タスクに特化しない様々なアプリケーションで、長期にわたってより良い結果を生み出し、勾配降下やエラー削減中に起こりうる多くの問題や分岐した結果を回避する、驚くべき実装を行いました。
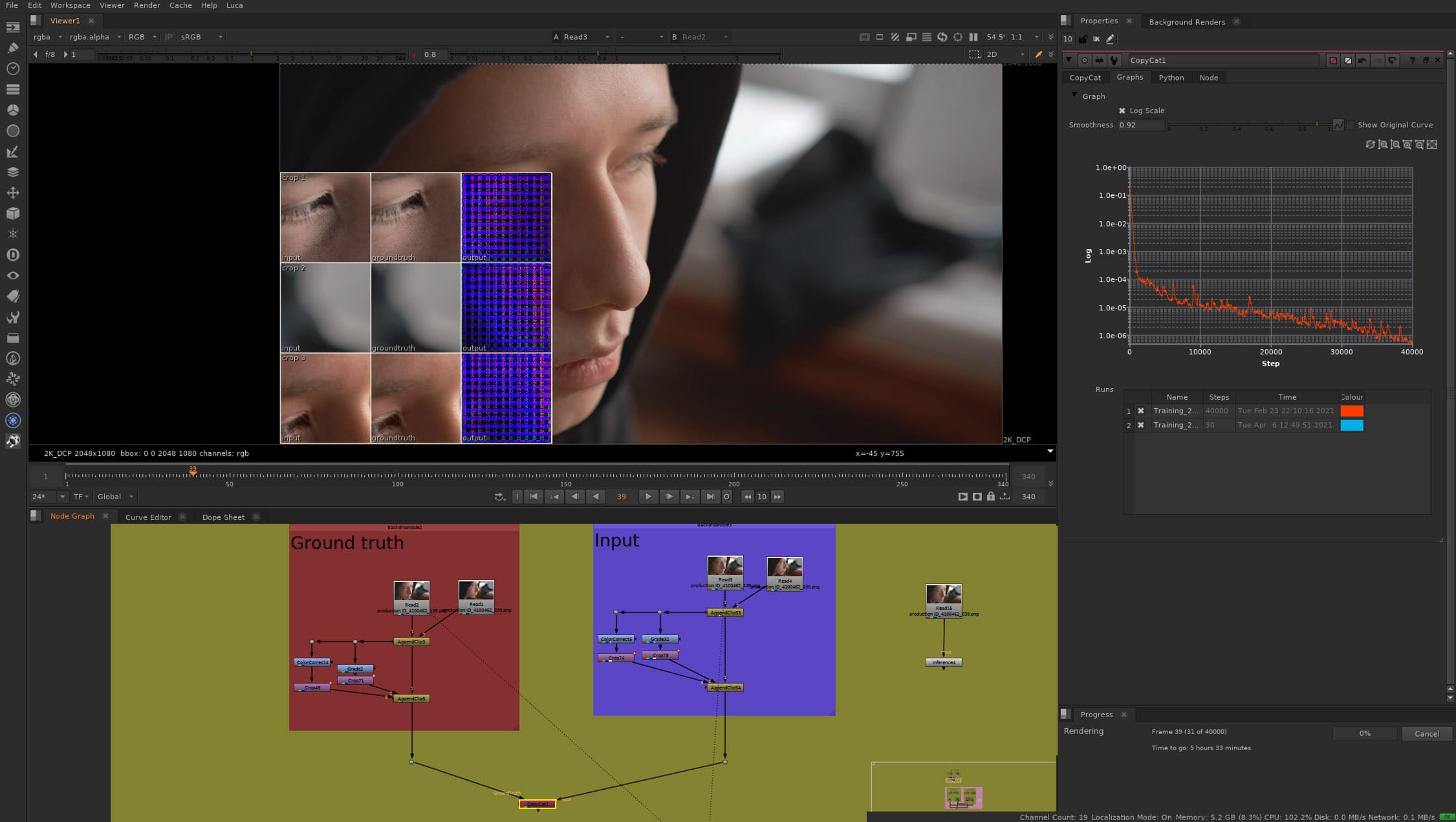
Foundryの非常に効果的なソリューションの重要な部分の1つは、オーバーフィッティングです。基本的に、VFXタスクのモデルをオーバーフィットさせることで、ショット内の膨大な冗長性を利用しつつ、従来のMLが捕捉しようとするショット間の大きな差異を横取りすることができます。MSRNネットワークはタスクに特化していませんが、Nukeのエンコーダー・デコーダーネットワークは、さまざまなタスクで非常に有効であることが証明されています。
「しかし、どのような場合でも、ドメイン固有の知識を適用しているからこそ優れているのであり、それこそが私たちのMSRNをチューニングする方法なのです」とRing氏は指摘します。AIRのチームは、MSRNをタスクのためにではなく、ピクセル精度、色忠実度、パフォーマンスへの要求が非常に高いVFXのためにチューニングしているのです。Foundryが直面する興味深い課題の1つは、MLが学術研究のホットトピックである一方で、一般研究者の焦点がVFXの世界の要求とあまりマッチしていないことです。
「アカデミアから完全に無視されている領域がたくさんあります。それは、学術的な論文と、撮影を時間通りに仕上げて納品することでは、目的が違うからだと思います」とRing氏は説明します。「この2つは非常に異なっています。例えば、SmartVectorを使いこなすために必要なプロセスと同じように、フィルタリングとフィルタ間の情報保持に細心の注意を払いました。これは、多くのMLモデルで、学習を早々に中止した場合に発生する典型的なアーティファクトを軽減する上で非常に重要です」と、Ring氏は付け加えます。
「特にHDR画像には注意が必要です。MLフレームワークは、歴史的に8ビットのsRGB画像に焦点を当てており、プロダクションレベルの画像にシフトすることは些細なことではありません」

CopyCatのようなMLノードで印象的なのは、トレーニングフレームがいかに少なくて済むかということです。これは、コンピュータがフレーム単位ではなく、パッチ単位で動作することに起因しています。ユーザーが提供するトレーニングフレームは5枚か数枚の「正しい」ものだけかもしれませんが、十分な時間があれば、これは推論を訓練し改善するのに十分です。
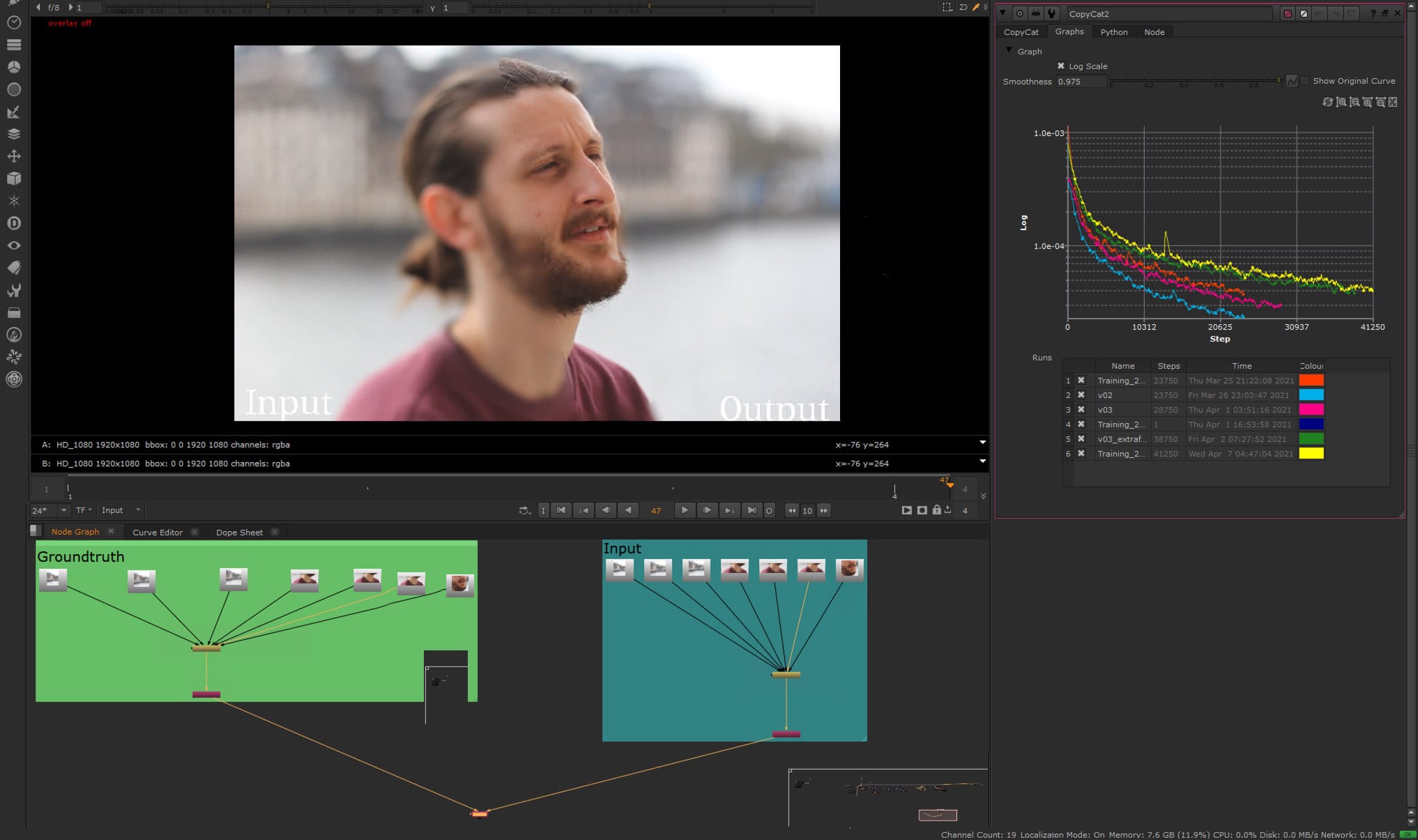
MSRNは、重みのセットを持つ層状のネットワークであり、これらの重みを調整することがMLの中核となる。デフォルトのネットワークは約42層で、重みは7Mになります。CopyCatでパラメータの大きさを変えることができます。スピード、品質、複雑さのどれを優先させたいかによって、他のネットワークサイズもあります。デフォルトの7Mの重みが調整され、これが.catファイルに保存されます(.catファイル1つあたり通常約26MBです)。
MLにとって重要なのは、ピクセルとパラメータの比率です。CopyCatが〜10個のパッチを使用する場合、各パッチは最大256x256pixels(262,144個の浮動値)である。「10個のパッチを使用する場合、合計で2Mの浮動小数点が必要となり、7Mの重みに比べて劇的に低くなります。
GPUカードに関するアドバイス
MLツールは、最新のGPUを使用してうまく動作します。AIRチームが使用している内部主力製品は、開発用のTitan RTX NVIDIAカードで、「追加メモリが素晴らしい」とRing氏はコメントしています。一般的に、ユーザーは推論を実行するために最低限のメモリを必要とします。
「現時点では、何かをするためには約7、8ギガのVRAMが必要で、これが最低ラインです。3080はまだ使っていませんが、A6000を使用しており、パフォーマンス転送の仕事では驚異的な性能を発揮しています。スイートスポットは、トレーニング用の24Gig/ Titan RTXです。私たちが前進するにつれ、多くのVRAMが必要になることが分かっています。もしあなたが今、何かを試してみようと考えているなら、現在のレベルのカード、例えば2080は素晴らしいです。もし、あなたが将来を見据えているのなら、3080は素晴らしいものになるでしょうし、3090も、もしあなたがそれを手に入れることができるのなら、間違いなくそうなります」
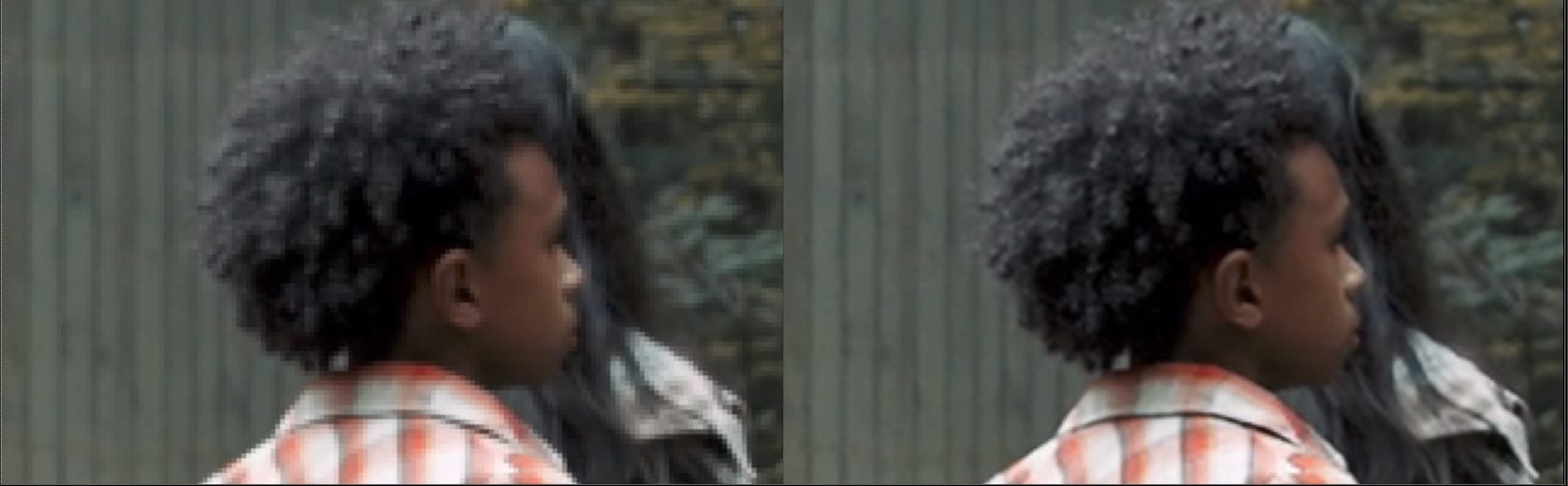
ML Serverは(まだ)死んでいない。
Nukeはアプリケーションであると同時にプラットフォームでもあります。多くの施設がC++ SDKやPythonを使ってNukeのコアから作り出しています。これをMLに拡張するのがFoundryの願いです。ハイエンドユーザーは、推論ノードに供給する独自の.catファイルを作成するMLプロセスを構築することが推奨されています。5年後には、チームが自分たちのモデルを構築し、Nukepediaのようなもので共有することを期待しています。すでにユーザーは、CopyCatからモデルを取り出し、自分の作業でそれを拡張することができます。しかし、これはML-Serverの利用を排除するものではありません。
ML-Serverは、それを使って仕事をし、本番で使っている顧客に対して、多くのオフラインサポートを提供してきました。Ring氏は「ML-Serverに関するオープンな『課題』を見ると、『NukeでMLを試す』という当初の目的をはるかに超えて、何が行われてきたかがわかります」
Inferenceとカスタム.catファイルについては、FoundryはすでにチームがPyTorchモデルを「.cat」ファイルにパッケージできるスクリプトの共有を開始しているが、いくつかの制限があります。例えば、4チャンネルの画像と、入力と出力の両方で同じ画像寸法しか存在できません。"計画では、より多様なモデルのサポートを追加し、変換スクリプトとトレーニングテンプレートをネイティブで含める予定です。これは、次のリリース(おそらくNuke 13.1)の一部になる予定です」とRing氏は説明します。
ML-ServerのGithubを見ると、ソフトウェアは11ヶ月間更新されていないので、現在の開発はあまり活発ではありませんが、AIRチーム自身は、顧客とモデルやアイデアを素早く共有したり、社内の調査のプロトタイプを作成するために、今でもこのソフトウェアを使用しています。「まだ問題を解決する準備ができていないんです」とリングは冗談めかして言う。

教師なし学習と強化学習
教師なし学習は、MLの中でも非常に強力で人気のある分野です。例えば、分類問題など、幅広く印象的な応用が可能です。 強化学習(RL)は、プロセスの改善やパーソナライズに威力を発揮する第三の分野です。そして、おそらくRLは、Nukeのユーザーエクスペリエンスの問題に適用できるかもしれません。言い換えれば、Nukeがユーザーにどのように見せるかについて、RLの役割があるかもしれません。私たちはDan Ring氏に、RLはユーザーが行うタスクを理解した上で、自分のNukeワークフローをパーソナライズするためのツールになりうると提案しました。AIRチームの課題は、「アライメント問題」と呼ばれる、NUKEがRLツールにとってタスクのバリエーションが多すぎるという問題を克服することでしょう。「私たちは、VFXのためのRLを探求することに非常に熱心で、最近採用した2人の社員はRLのバックグラウンドを持っています!確かに私たちにとっては長い時間軸になりますが、私たち(そしてお客様)はそれが何を意味するのかを考え始めています」と答えました。
2つの例がよく出てきます。1つ目は、Ring氏が「MS Clippy / auto-comp my shot」と呼んだアーティストのタスクです。ユーザーが何をしようとしているのかをシステムが察知し、ショットを「オートコンプリート」することができるのか。ここで「価値観の一致」の問題がすぐに出てきます。アーティストの場合、アーティスト(監督者)が知識や指示を与えなければ、「本当の価値・報酬」のシグナルを導き出すことは難しいことが多いです。理想は、アーティストやシステムがグリーンスクリーンからどれだけキーを引き出したかを知りたいのであって、客観的ではないのです」と説明する。「このようなオンラインの半教師付き学習には多くの価値がありますが、厳密にはRLではありません。私たちが測定できる客観的な信号のひとつに、時間、つまり『ノードに滞在した時間』があります。RLシステムなら、それを使って、ノードの調整にかかる時間を最小化するための最適なノブ値のセットを決定することができます。繰り返しになりますが、アーティストの滞在時間を短縮するシステムが、アーティストが行っているタスクにうまく合致しているかどうかは分かりませんが、それを見つけるのが楽しみです!」
2つ目の応用例は、Nukeアーティストを支援することに焦点を当てたものではなく、VFXプロデューサーが 「このショットはいくらかかるのか?」という質問に答えるためのものです。一般的な入札問題は、いくつかのショットがあり、それぞれのショットが様々な品質レベルで様々なタスクを必要とすることに基づいています。AIRチームは今、「システムがショットを提供し、コストを削減するためのステップのリストを推論できるか」と問いかけています。ここでの整合性ははるかに明確で、客観的に測定することができます。しかし、Ring氏は、これがプロデューサーに取って代わるものではなく、プロデューサーを助けるためのものであることもすぐに指摘する。「優れたVFXプロデューサーは、その経験とデータ処理能力の総和以上のものです」
一人のアーティストが成し遂げなければならない仕事の量は、昨年から爆発的に増えています。アーティストを支援するためには、物事をより速くする必要があり、それはスケーリングを意味します。オンプレミスのマシンを増やすか、クラウドでの処理を増やすか、どちらかです。「リソースをめぐる深刻な競争に巻き込まれると、スタジオのパフォーマンスは低下します。そこで、RLの一分野であるQ-learningがどのように役立つかを考え始めました」とRing氏は言います。「特に、ある負荷の計算環境において、グラフの評価とレンダリング時間を最小化するために、Katanaの計算とデータ転送の最適な順序を推論するシステムは可能だろうか?」AIRチームはまだ調査中ですが、すでに、大規模なアプリケーションやコア外の計算を多用するアプリケーションは、AIやMLのスケジューリングを巧みに使って設計するべきだと考えているようです。
ロト
おそらく、最も求められているMLソリューションは、ロトを解決するものでしょう。CopyCatは非常に優れたアルファやマットを作ることができますが、Ring氏が指摘するように、ネットワークが学習するための高品質のトレーニング例を生成するためには、やはり優れたアーティストが必要です。CopyCatは「悪いマットを良くするのではなく、悪いマットをより早く与えるだけ」です。CopyCatのマットは素晴らしいものですが、ロトを完全に解決するには、天才レベルのAIが必要です。Foundryが発表したデモでは、CopyCatがいくつかのロトショットを白黒マットに加工していますが、ロトの一般的な解決はまだ少し先の話です。ロトがこれほど複雑である理由は、3つのポイントに集約されます:
- セグメンテーションなどのMLソリューションの多くは、出力が白黒マットであることを前提としています。CopyCatはマットを作るのに有効ですが、ロトの問題はマットを最終出力とするのではなく、アーティストが調整し変化させることができる編集可能なスプラインシェイプを対象としているのです。このように、マットはキーフレーム化されたスプラインシェイプとして表現され、時間と共に感覚的に動くようになっています。Nukeアーティストがロトを調整できるようにするためには、ソリューションが単なるピクセルマスクのマット出力であったり、1フレームごとにキーフレームされたスタンドアロンのスプラインであったりすることはできません。
- ほとんどのMLソリューションは、時間的なものではありません。これは、華麗なデジタルメイクの例から明らかではないかもしれませんが、解決策は追跡されたパッチではなく、フレームごとに独立した解決策であり、それらはたまたまちらつかないように互いに接近しているのです。しかし、MLのロジックは、クリップを解決するのではなく、一連のフレームを解決するものなのです。これは、ロトの問題とは相性が悪い。優れたロトは、キーフレームを10フレームごとではなく、モーションの頂点に正しく配置します。
- ロトアーティストは、ロトの出力として、現在のシルエットやアウトラインだけを求めているわけではありません。歩く人のロトは、腕が体の上を動くので、形が重なり合っています。優れたロトアーティストであれば、ロトを組み合わせたアウトラインが奇妙な形の塊であっても、オブジェクトにとって意味のある形状をアニメーション化します。
Foundryはロトを完全に解決するには全体像が必要であること、アーティストが操作できるスプラインツールを作成する能力が必要であることを知っています。朗報もあります。2019年からバース大学、ユニバーシティ・カレッジ・ロンドン、DNEGとの共同研究プログラムであるスマート・ロト(Roto++)と呼ばれる内部プロジェクトがあります。今のところ、CopyCatは素晴らしい仕事をしてくれますが、非常に画素数の多いソリューションです。このようなアプローチには利点があります。CopyCatは滑らかな時間的スプラインにこだわらないので、トレーニング用の合成データを作るのが簡単です。合成データとは、あるフレームに対してロトを手作業で作成し、それをフレーム上にランダムな角度で複製したもので、様々な背景を想定しています。MLノードはマットから非マットへの移行を学習したいだけなので、シーケンスに意味をなさない偽フレームから学習することができますが、マットと非マットの学習データをより多く提供します。
ロトの時間的形状アニメーションは、AIの他の分野からも恩恵を受ける可能性があります。 The Foundryが独自に行った調査によると、ロトの半分強が人間であると推定されています。人物は、手足、特に指や手のオクルージョン、髪の毛やルーズな服装に関する問題のために、ロトするのが難しいのです。そのため、特殊なケースに対応した人物ロトツールの開発を検討する価値があります。平坦な2D映像から3Dの人間の骨や関節の動きを推定することについては、すでにいくつかの素晴らしい研究論文があります。また、MLボリューム再構成の研究も盛んで、この2つの分野は、将来、より強力な人物に特化したロトAIソリューションの追加入力となる可能性があります。
アーティストの手助けをする(置き換えるのではない)
より長期的に考えると、CopyCatはNukeのアーティストにとって強力なツールであり、MLに関する基礎固めや期待値を設定するのにも役立ちます。VFXにおけるMLの垂直方向のヘッドルームは非常に高く、RLやQ-learningのようなものは、適切なタスクに適切な考え方で適用すると、大きな影響を与えることができます。
また、MLの性質として、トレーニングには時間がかかるが、解決策や推論が光速になることが多いので、Nukeをリアルタイム空間での使用に開放することも重要である。モアレの修正、撮影中のリグの除去、LEDキャプチャーボリュームの微分角色収差など、インカメラVFXで発生する新しいコンプ問題の解決に、CopyCatが使われ始めています。LEDスクリーン自体のダイナミックレンジの狭さや、物理的なライトや壁との相互作用などの性質により、VP(バーチャルプロダクション)ではNukeが使用されていない領域が多数存在します。スタジオ、VP、VFXベンダーは、"その日のうちに持ち帰れる "と約束されていますが、これらの新しい問題は、撮影がポストで行われることを意味します」とRing氏は指摘します。「私たちは、これらの問題を可能な限り撮影現場で軽減するためのツールセットを調査しています。UEのレンダーパスやカメラを簡単にNukeに取り込むことができるGENIO(Nuke / Unreal bridge)ワークですでに始めていますが、壁のセットアップ中にリアルタイムのCopyCatをトレーニングし、ライブマットを生成するために使用する世界も想像できます。すべては、その日に最終的なイメージを提供するという共通の目標のために。
Foundryは、VPとNukeのワークアラウンドとして、決定の「永続化」、現場データの扱い、マスター共有タイムラインへの適合(「Timeline of Truth」)についても調べています。「ご想像の通り、データの収集と管理は、ML(おそらく我々の業界で最も困難な問題の1つ)よりも困難な問題であり、さらに先の話です」とリングは締めくくります。