AutodeskがWonder Dynamicsを買収したと発表されました。Wonder DynamicsはCGキャラを自動的にアニメ、ライティング、合成する AI ツール「Wonder Studio」をリリースして話題 […]
CG News
AutodeskがWonder Dynamicsを買収

![]()
AutodeskがWonder Dynamicsを買収したと発表されました。Wonder DynamicsはCGキャラを自動的にアニメ、ライティング、合成する AI ツール「Wonder Studio」をリリースして話題 […]

Googleの動画生成AI「Veo」が発表されています。高解像度で1分を超えるビデオ生成が可能なモデルとのことです。また、画像生成AIの「Imagen 3」も発表されました。OpenAIのSoraと比べてどうなるのか興味 […]

Autodeskが生成AI3D形状作成のための研究プロジェクト「Bernini」を発表 しました。2D画像、テキスト、ボクセル、点群など様々な入力から機能的な3D形状を素早く生成するモデルのようです。現在は研究段階で、ど […]
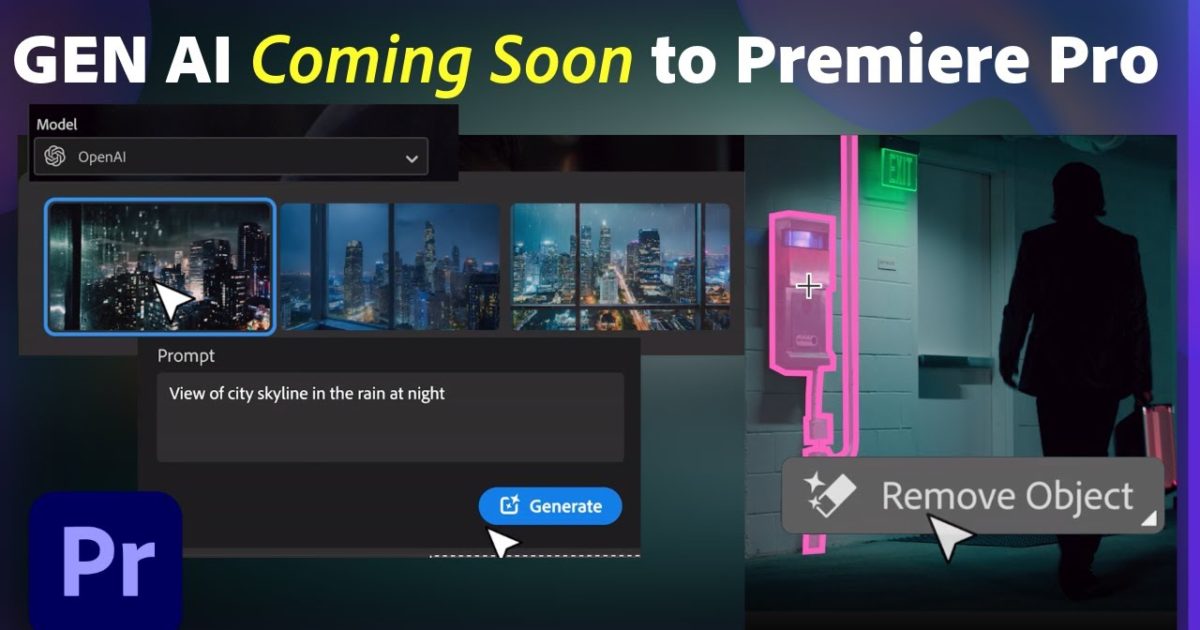
AdobeがPremiere Proの生成AI機能の導入を発表しました。ビデオの尺を伸ばす「ジェネレーティブ・エクステンド」、AIベースのスマートマスキングとトラッキングツールによる「オブジェクトの追加と削除」、「ジェネ […]

UnityがZiva製品の販売、技術サポートの終了をアナウンスしました。Ziva製品は2022年に買収したMaya用のVFX向けプラグインです。技術は引き続きUnityが保持するようです。 https://blog.un […]

アニメのセル彩色を行う学習モデルが公開されています。最初の1フレームをペイントすると、それ以降のフレームを自動的に彩色するようです。3Dデータを使用して学習してるようですね。 https://ykdai.github.i […]

実写のAI変換を使用したアニメ制作サービス「アニムビ」のサイトが公開されています。生成AIで作成した楽曲制作にも対応しているようです。 名古屋の株式会社K&Kデザインと 株式会社タジクが立ち上げたサービスのようで […]

生成AIのアップスケールをレンダリングの品質向上に利用するのはどうか?という興味深い記事が公開されています。 CGだと草のモデルをスキャッターするとパターン感が出てしまったり、テクスチャのリピート感が出てしまうことが多い […]

機械学習を使用したリライティングサービス「SwitchLight」のNuke版プラグインが開発中のようです。

Adobe が Substance SamplerとStagerに生成AIを発表しました。テキスト プロンプトからタイリング可能なテクスチャを生成したり、背景用の画像を生成できるようです。 https://blog.ad […]

Nvidia がテキスト プロンプトから現実世界のオブジェクトのテクスチャ モデルを生成する「LATTE3D 」のデモ ビデオを投稿しました。 https://blogs.nvidia.com/blog/latte-3d […]

単一画像からの高速に3Dオブジェクトを生成するモデル「TripoSR」が公開されています。 https://stability.ai/news/triposr-3d-generation https://github.c […]

V-Rayを開発するChaosが、今後のChaos製品についてライブ配信しました。AI技術やV-Ray for Blenderに取り組んでいることが語られました。 https://www.chaos.com/blog/c […]

OpenAI の新しいテキストからビデオ生成モデル「Sora」のページが公開されました。現実世界での物理的な世界の動きを理解し、シミュレートするためにAIだそうです。 https://openai.com/sora &n […]

Chaosが開発中のAI技術「Chaos next」を発表しました。詳細は2月27日のライブイベントで紹介されるのかな? どの技術も実現できたら便利そうです。 https://www.chaos.com/next &nb […]