VFXにおけるAI、機械学習に関する記事が公開されていたのでメモしておきます。
https://www.fxguide.com/fxfeatured/the-art-and-craft-of-training-data-yes-training-data/
トレーニングデータの芸術と技術
機械学習の学習データ構築に活用されるVFX
機械学習(ML)は、VFXのさまざまな問題を解決するためのアプローチとして注目を集めています。しかし、MLがVFXのために何ができるかが注目される一方で、MLソリューションのトレーニングデータを作成することに焦点を当てたVFXの新しい分野も存在します。Houdini、Nuke、その他多くのVFXツールは、トレーニングデータの生成にクリエイティブに使用されており、この傾向はさらに拡大することが予想されます。より深い理解を得るためには、MLプログラムの根本的な性質を調べる必要があります。
学習ソリューションとしてのML
機械学習ソリューションを作る前に、解決すべき問題と、MLアプローチが機能するために必要なことを理解することが不可欠です。特に、どのようなデータがすでに世の中に存在しているのか、そしてそのデータを使って問題を解決できるのか、ということです。一見すると、可能な限り大量の "ground truth "や完全な例が欲しいだけだと思われるかもしれないが、それは現代のMLを効率的に訓練する方法ではありません。
教師あり学習データと教師なし学習データは、機械学習で使われる2種類のデータです。教師あり学習データは、機械学習モデルの学習に使われるラベル付きデータです。つまり、入力データには正しい出力がラベル付けされ、モデルは入力データに基づいてこれらの出力を予測するように学習しkます。一方、教師なし学習データは、機械学習モデルの学習に使用されるラベル付けされていないデータです。この場合、モデルは、何を探すべきかについての特別なガイダンスなしに、データのパターンと関係を学習することを意味します。
教師あり学習データと教師なし学習データにはそれぞれ長所と短所があり、そのどちらを選択するかは、解決しようとする特定の問題と利用可能なデータに依存します。しかし、MLに詳しくない人にとっては、どちらの場合もデータが多ければ多いほど良いと思われがちです。そうではありません。
どちらのMLモデルにも、データをキュレーションするためのアートとサイエンスがあります。 例えば、オブジェクトのテクスチャを完全に「間違った」ものに変えると、ニューラル解を構築する際に、学習データをよりジオメトリに集中させ、表面特性から偏らせる効果があります。植物の葉を識別する分類器があったとして、その植物の品種を特定する最良の手がかりとなるのは、本当は葉の形状やエッジの詳細であることがわかっているとします。データセットのサブセットを作成し、表面特性を「低く評価」することで、自動車の塗料で作られたような、奇妙な表面特性を持つ葉のセットを混ぜることができます。自然界の葉が車の塗料で栽培されることはないので、これは明らかに誤りですが、MLから見れば植物の品種を識別するために表面特性に頼ることができなければ、葉の形状により傾倒するでしょう。つまり、VFXアーティストが車の塗料で植物を作り、MLのソリューションを指示したりキュレーションしたりするために雇われる可能性があります。 これは合成データの例です。この特別なアプローチは、「ディストラクター」を使ったドメインランダマイゼーションとして知られています。

合成データ
ビジュアル エフェクト ツールを使って合成データを作成することは、ML用の大規模で多様なデータセットを生成する方法として、ますます一般的になってきています。この種のデータは、実世界の学習データが不足している場合や、実世界のデータを入手するのが困難または高価な場合に使用されることが多いです。VFXソフトウェアは、リアルな仮想環境、オブジェクト、キャラクターを作成し、有用なシナリオで操作したり撮影したりするために使用できます。VFXを使用することで、稀な出来事や危険な状況など、現実では入手が困難または不可能なデータを作成することができます。さらに、照明、天候、カメラアングルを制御できるため、データ生成プロセスや入力可能性のバリエーションをよりコントロールできます。また、上述したように、MLソリューションの舵取りをする方法として、非常に明らかに「間違った」データを作成するために使用することもできます。 その結果、合成データはMLやコンピュータ・ビジョンのアプリケーションにとって不可欠なツールになりつつあります。
COVIDの期間中、多くの企業がVFXベースの合成データの利点を発見しました。例えばアメリカのある農業会社は、グラウンドトゥルースデータ用の写真を撮影するために人を畑に呼ぶことができなかったので、代わりに合成データでトレーニングを行いました。VFXではMLを訓練してrotoを向上させたい場合、人間のアーティストがセグメンテーションマップのために様々な個々のフレームに注釈をつけたり、ロトスコープで切り出したりすることができますが、アニメ化されたデジタルヒューマンを使って合成的にセグメンテーションマップを作成するのに比べて、ノイズが入ってしまいます。ここでは「ロト」セグメンテーションは、実際に3Dシルエットがあることに基づいてフェイクされていますが、非常に正確なものになります。100%正確で高品質なデータを作成することができ、従来の手法で見られるような欠陥は一切ありません。
合成トレーニングデータとは、人工的に生成されたデータのことで、現在すべての主要AI企業でMLモデルのトレーニングに使用されています。NvidiaやGoogleをはじめとする多くの企業が、生成的敵対ネットワーク(GAN)、ニューラルネットワーク、VFXシミュレーションツールなどを使って合成トレーニングデータを生成しています。
合成データは、以下のような様々な手法を用いて生成することができます。
- データの増強
- GAN推論
- 3Dアニメーション
- シミュレーション
- ディストラクター
- アブレーション
- 合成少数オーバーサンプリング技術
- 交絡因子の修正など
- その他多くの方法があります
合成訓練データの目的は、機械学習モデルの訓練に使用できる大規模で多様なデータセットを作成し、その精度を向上させることです。なぜなら、合成学習データは多くの場合、より効率的に生成され、役に立つ対応する追加メタデータを提供してくれるからです。例えばあるアプリケーションの学習に、デジタルヒューマンの顔を使用することができます。それは、より正確でリアルに見えるからではなく、非常に正確な表面法線を提供できるからです。
多ければ良いというものではない
MLソリューションを作成し、特にキュレーションするには、解決しようとする問題、使用されるデータ、適用されるMLアルゴリズムを深く理解する必要があります。これは高度なスキルと要求の高い(人間の)役割となり得ます。構造化されたアプローチに従い、継続的に反復と改善を行うことで、MLソリューションは複雑な問題を解決し、イノベーションを推進するための強力なツールとなり得ます。MLが膨大なデータを持っているからといって、必ずしも精度が高いとは限りません。アカデミー賞受賞者のライアン・レイニーは、2021年にfxguideに対し、彼の長編ドキュメンタリー映画『Welcome to Chechnya』のためのトレーニングデータの撮影について、このように説明しています。
バイアス
長編映画を制作する際、レイニーは適切なトレーニングクリップの選択に集中することが重要なステップであることに気づきました。どの証人の顔にも置き換え可能な膨大なトレーニング素材から、注意深く厳選されたサブセットのみが使用されました。このプロセスでは、トレーニングデータを追跡し、ヘッドアングル、色温度、照明のマッチングに基づいてフレーム/クリップのセットを自動的に生成するために、いくつかの機械学習ツールが導入されました。特定のトレーニングデータは、データセットの「顔」エンコーディングに基づき、NumPy - ユークリッド距離、「ビッグテーブル」ルックアップ手法を使用してマスターデータベースから引き出されました。顔のエンコーディングは、顔の角度と表情に基づいています。

各俳優は、同じ演技を複数のアングルで撮影するために、周囲に複数のカメラを配置して撮影されました。カメラのセットアップ中、実際のシャッターコントロールは同期して制御することができませんでした。その結果、ライアンはただカメラを回し、テイク間のカットはしませんでした。その結果、意図的なテイクと、俳優が片側に寄って監督と話している間のランダムな録音の両方をトレーニング映像として残すことになりました。その結果、トレーニングデータ全体として、俳優の顔の片側(俳優が監督と話すために振り向いたときにカメラに映る側)に偏りが出てしまいました。ライアンは、これこそが避けるべき偏ったトレーニングデータであると指摘しました。
ライアンの例は、トレーニングデータに望ましくないバイアスがあることですが、MLトレーニングの技術に長けていれば、コントロールバイアスを導入することも同様に有効です。MLのソリューションには批判的な目でアプローチすることが重要であり、ハイテクでAIを使っているからといって、そのソリューションが正しいとか優れていると単純に信じてはいけません。基礎となるデータと仮定を調査し、使用されているトレーニングデータの限界を考慮することが不可欠です。
さらに詳しく知るために、エヌビディアとグーグルのML専門家に話を聞きました。

NVIDIA
ポール・キャレンダー氏は、NVIDIAのレプリケーター・チームのテクニカル・アーティストです。NVIDIAは機械学習分野において、間違いなく今世界で最も勢いのある企業であり、その事実は、上場企業としての急速な収益と株価の躍進に反映されています。

NVIDIAには、SimReadyアセットを作成するための開発者ツール一式があります。SimReady(シミュレーション対応)アセットとは、物理的に正確な3Dオブジェクトのことで、正確な物理特性、挙動、メタデータを持ち、シミュレーションされたデジタル世界(および/またはデジタルツイン)で現実世界を表現します。SimReadyアセットは、Universal Scene Description (USD)を使用して構築され、NVIDIAのオープンソース、スケーラブル、マルチプラットフォーム物理シミュレーションソリューションであるPhysXで最大限の精度を得るために、現実世界と同じように動作するように構築されています。
NVIDIAのSIM Readyアセットは、通常のVFX要件を超えるものです。SIM Readyアセットは興味深いもので、ポール・カレンダー氏は、「アセットでは、多くのプロパティや属性をランダム化することができます。 VFXアセットのいくつかの側面は、マテリアルプロパティなど簡単に変更することができますが、一般的には、メッシュを分離したり、異なるピースに分割したりするようなことをしたい場合は、すべてを完全にパラメータ化するのが理想的です」 Sim Readyアセットでは、可能な限り多くのプロパティをプロシージャルにランダム化することができます。
同社のOmniverseツールキットとSDKの一部として、Omniverse Replicatorと呼ばれる特定の合成データ生成があります。これは、合成データ生成に特化したOmniverseの拡張機能です。NVIDIAのOmniverse Replicatorは、研究者や開発者が物理的に正確な合成データを生成し、MLネットワークのトレーニングを加速するためのカスタム合成データ生成(SDG)ツールを簡単に構築することを可能にする中核部分です。ポール・キャレンダー氏は、「これはすべてPythonicで、SDGシミュレーションを作成するためのOmniverseの他のすべての側面と統合されており、合成データを生成するために使用できます」とコメントしています。

MLによるVFXの「トリック」には、一般的なものがたくさんあります。例えば、ビジュアル・オブジェクトの部分的な非表示バージョンを作成するといったものです。もう1つの興味深いMLのコンセプトはアブレーションと呼ばれるもので、ポール・キャレンダー氏はこう説明します。「データセットは、テクスチャのランダム化、照明のランダム化、ノイズの追加など、様々なバリエーションで生成されます。アブレーションは、ランダム化がどの程度パフォーマンスに有効かをテストするために、ランダム化の種類を1つずつ削除するセットを作成します。これは、SDGチームがバリエーションがデータセットにどのような影響を与えるかを理解するのに役立つツールの1つです」
合成データに使用されるVFXに関して、カレンダーはSDG(合成データ生成)の段階を次のように分類しています。
- アセット
- シーン構築
- シミュレーション
- データ生成
「アセット生成は、伝統的なVFXにとって最大の分野です。なぜなら、"ドメインギャップを埋める "ために様々なアセットや環境が飽くことなく必要とされ、現場の真実に近づくことができるからです」と彼は説明します。「HoudiniとBlenderは、プロシージャルであるため、特に注目に値します」プロシージャル性とSimReadyアセットは、SDGのバリエーションを作成しパラメータ化するためのソリューションの一部です。「私たちは、アセットを取得し、シーンに入力するためのプログラム的アプローチに傾倒する必要があります。そのためには、すべてのアセットが分類によって自分が何であるかを "知っている "必要があります。 理想的には、シーンの生成とキャプチャの実行中にこれを行い、変更できないハードな "ベイクダウン "アセットに頼らないことです。これが、リアルタイム・ソリューションが望ましい理由のひとつです。SDGの修正とレンダリングと生成の速度は、潜在的に非常に速いのです」
コンポジティングのような伝統的なVFXのコンセプトも、SDGに類似しています。「センサーノイズやピクセル色域のマッチング、さらには光の吹き出しのマッチングも、グランドトゥルースにそれらのアーティファクトが含まれている場合には重要になります」このようなアーティファクトは、合成中やグレーディング中に、多くの場合リアルタイムで、あるいはポストプロセスとして適用することができます。「必要な効果を達成するために、OpenCVや他のpythonフレンドリーな画像ライブラリのようなライブラリを使用して、ポスト補強が通常行われます」通常NVIDIAは、シーン自体のライティングのバリエーションなど、主要なバリエーションにマッチさせようとします。「すべてをシミュレートすることで、現実に近づくことができ、シーン内のライトのフォトメトリック特性をマッチさせることで、プログラム的に数値を微調整しても、意味のある一貫した結果を得ることができるからです」
SDGは他ではできないことを解決してくれるので、非常に重要なのです。「画像内の車両が非常に小さく、アノテーションを行う人が、それらがどのクラスの車両であるかを識別できなかった例を見ました。 SDGは、画像内のレンダリングの大きさに関係なく、それらの分類を知ることができます」。この場合、SDGを含めると、AIモデルは遠くの車両を認識する性能をより引き出すことができました。
ポール・キャレンダー氏は、MLは退屈なデータ整理や平凡な作業とは程遠く、SDGは「探偵や錬金術」に似ていると指摘します。「AIは人間のように特徴を認識したり検出したりはしません。だから、何かがどのように見えるかについて、私たち自身の先入観に従うだけでは必ずしも正しいとは限らないのです」 このため、優れたSDGを生成することは、シーンを生成するアーティストと、データ上でモデルをテスト・訓練するMLエンジニアの間の反復プロセスであると彼は考えています。
「私たちのチームは、シーンの本質的な部分を探り出し、合成的にシステムを再構築して、大量のデータをプロシージャルに構築しています。VFX(およびゲーム開発)には、まさにこのような長い歴史があると常に感じています。リファレンスからビジュアルを作成し、結果を達成するために、多くの場合プロシージャルで、多くの場合シミュレーションとして、システムを考案するのです」
結局のところ、ポール・キャレンダーのようなアーティストは、SDGを成功させるために、VFXやゲーム業界で一般的なツールを深く利用しています。「それはエキサイティングな空間であり、スキルのマッピングは非常にうまくいっています」

GoogleのSynthetic Teamは、プロダクションで使用される一般的なVFXツールの多くを使用しています。Houdini、Blender、Maya、NukeなどのDCCツールです。「パイプラインとワークフローは、過去のVFXにインスパイアされていますが、VFXハウスと同一ではない環境で統合されています」とGoogleのルカ・プラッソ氏(元Dreamworksシニアテクニカルアーティスト)はコメントしています。「私たちは、多くのカスタムおよび独自のツールやコードをミックスに加え、テックアーティストが私たちのエンジニアリングスタッフと一緒に働いています」と指摘します。「機械学習における合成データの役割と使い方は日々進化しており、データの生成と消費の方法はプロジェクトによって異なります。

Googleのチームは、世界を "見て理解する "ためのアルゴリズムを訓練するために使われる、一般的な合成3Dシーンに焦点を当てています。多くの場合、この世界は複雑で、三次元で、アニメーションで、GANや同様のアルゴリズムではまだ再現できない多くの情報の層でできています。同時に、新しいテクニックは "伝統的な "パイプラインに居場所を見つけます。例えば、モーションは単にモーキャップで生成するのではなく、合成することができます。シーンや写真のリライティングやリレンダリングは、例えばNeRFアルゴリズムを使って、新しいエキサイティングな方法で行うことができます。 (NeRFの説明については、fxguideの記事を参照)
チームにとっての挑戦は、合成パイプラインを大規模に開発しながら、こうした急速な変化に対応できるようにすることです。合成データがMLで有用なのは、現実世界では必要なスケールで簡単に取得できないデータを生成できるからです。合成データは、人間のアノテーターによってもたらされる "ノイズ "に悩まされることなく、正確で、アノテートされ詳細です。「多くの場合、合成データは、実世界からデータを収集し始める前であっても、新しいアルゴリズムの設計のブロックを解除することができます」と彼は説明します。
合成データシステムの設計における課題のひとつは、バイアスにどう対処するかということです。「例えば、アルゴリズムにペンを認識させる必要がある場合、形状、材質、外観、手触りを制御し、これまでに製造されたあらゆるペンを生成できる手続き的システムを設計します。このようなシステムを設計する際には、例えばボールペンのみを設計するような偏りが生じないようにする必要があります。実際のデータを取得し始めると、そのようなバイアスを取り除き、実際のデータにできるだけ近いものを作成するために、デザインの選択を常に再評価する必要があります」HoudiniのようなプロシージャルVFXツールは、チームが取り組まなければならない多くの作業に適しています。「私たちのチームは、新しいハードウェアセンサーが利用可能になる前にデータを作成するよう求められることがよくあります。このようなアプローチは、従来のDCCツールで可能なことをシミュレートし、研究開発を解き放ちます」
「以前はPDI/ドリームワークスで子供や両親の観客のために映画を作っていたのに、今はアルゴリズムだけが見るような映画を作るなんて冗談だ......僕はアルゴリズムのために映画を作るんだ。幸いなことに、続編を作るとき、アルゴリズムはうるさく言わないんだ!]- ルカ・プラッソ
スケール設計もまた別の課題です。MLアルゴリズムの中には、非常に多くのデータを必要とするものがあります。「数千の画像/シーン/バリエーションが必要なのではなく、数百万、数千万が必要な場合もあります。そのような場合、7分の長編映画クリップを作成するために設計されたVFXのようなパイプラインを、作成する必要があるすべてのデータセットに対して複製することができます」
Googleも独自のパイプラインや技術を持っており以前から実装し取り組んでいるが、彼らのMLエンジニアはSIGGRAPHやCVPRのようなカンファレンスで研究成果を発表する傾向があります。「グランド・トゥルースの実データは、これらのシステムのほとんどを設計する上で非常に重要です。私たちの仕事の根拠となり、アーティストがワークフローに不必要なバイアスを持ち込むのを防ぎます。私たちの仕事がうまくいけば、私たちのデータは(必要とされる品質とスケールの限界内で)可能な限りグランドトゥルースに近いものになります」
Googleはまた、トレーニングデータのキュレーションも機械学習プロセスの重要な部分としています。「キュレーションは、合成データと実データの測定と正確なラベリングに大きく関係しています。これによってML研究者は、トレーニングで安全に使用できるデータを特定し、比較対照し、より良いアルゴリズムのパフォーマンスを達成するために、実データと合成データの適切な "比率 "を見つけることができます」
合成データの最も単純な形
合成データは、現実世界で撮影されたグラウンド・トゥルース・データの代わりとなるオリジナルの画像やデータを新たに作成するために使用する方法と、オリジナルのグラウンド・トゥルース・トレーニング・データを補強、補足、構築するために使用する方法があります。2つ目のケースは、トレーニングデータとして使用される可能性のある画像を取得し、それを反転させ、回転させ、人間の目には些細に見えるが、実際にはトレーニングデータに膨大な乗算効果をもたらすような方法で調整する自動化されたプロセスが存在します。PyTorchのような様々な機械学習ツールでは、学習データを9倍にする自動化された機能を備えていることも珍しくありません。アフィン変換とは、画像を反転(ミラーリング)するように、直線や平行度は保持するが、必ずしもユークリッド距離や角度は保持しない幾何学的変換のことです。
次元と深度
機械学習では、次元とはデータ・ポイントを表現するのに使われる特徴や変数の数を指す。例えば、データ・ポイントは3つの次元を持ち、その高さ、幅、深さを表す。データセットの次元数は、MLモデルの精度に大きな影響を与える可能性があります。機械学習における深さとは、ニューラルネットワークのレイヤーの数を指します。ニューラルネットワークは複数のレイヤーから構成され、それぞれが情報を処理するニューロンを含みます。ネットワークのレイヤー数はその深さを決定し、これはモデルの精度に大きな影響を与えます。より深いネットワークは、データのより複雑な関係をモデル化することができるため、より正確な結果を出すことができます。トレーニングデータのキュレーションの重要な側面の1つは、MLパイプラインの次元と深さに基づいて、適切な量と種類のデータを提供することです。
交絡因子の修正
MLにおける重要な洞察は、交絡因子がニューラルネットワークモデルの予測性能に悪影響を与える可能性があるということです。MLは複雑な問題を解くのに強力だが、欠点がないわけではありません。MLの最大の課題の1つは交絡因子の存在です。交絡因子とは、MLモデルの精度に大きな影響を与えうるが、モデルの出力には直接関係しないデータ中の変数のことです。例えば、画像中の猫を識別するために学習されたMLモデルにおいて、猫の毛色は、猫を識別するというタスクには直接関係しないが、モデルの精度に影響を与える可能性があるため、交絡因子となる可能性があります。これに対処するためには、モデルを学習する前に、データ中の交絡因子を特定し、それを考慮することが重要です。これは、特徴選択、データの前処理、またはデータのキュレーションなどのテクニックを使用することによって行うことができます。
これらの課題の1つは、このような交絡因子の存在に起因する、ディープラーニング手法によって抽出された「誤ったシグナル」を除去することです。このような認識ミスを認識した上で、経験的な証拠によると、ディープニューラルネットワークは、一見よく訓練されたディープラーニングモデルが、ラボで収集/管理されたデータセットでは高い予測力を持つにもかかわらず、外部データセットでは限定的な予測性能を示すような、交絡要因からシグナルを学習することができます。
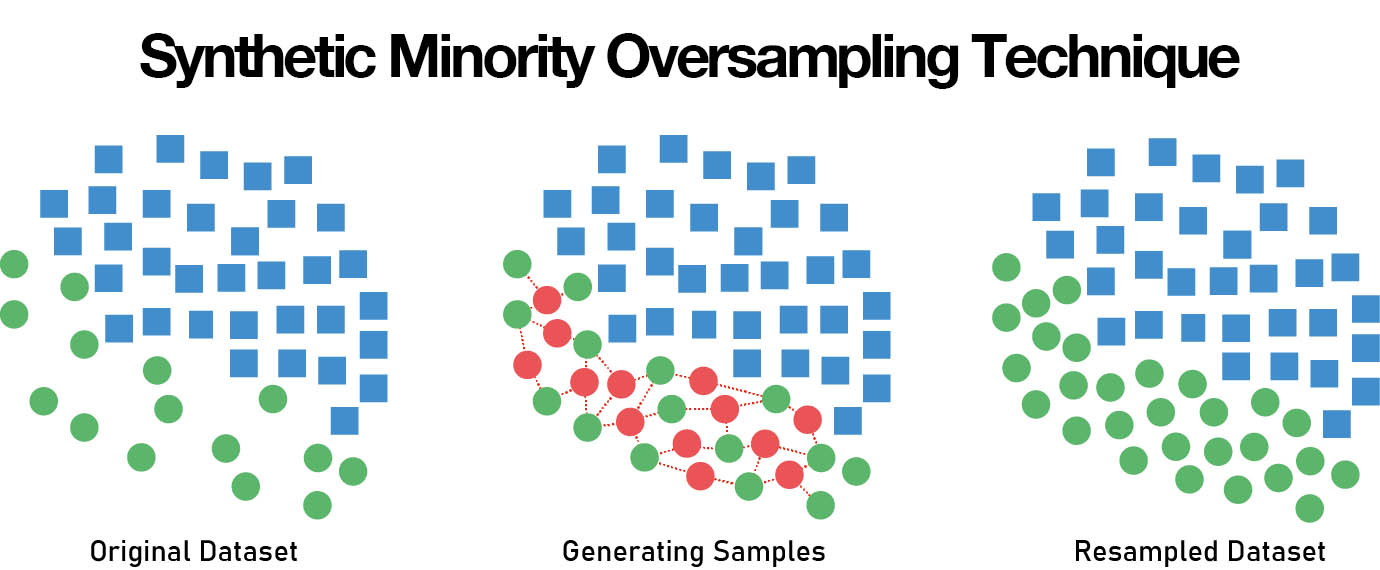
少数特徴とSMOTE
MLにおいて少数特徴とは、他の特徴に比べて出現数が少ないデータの特徴です。これらの少数特徴はMLモデルの精度に大きな影響を与える可能性がありますが、数が少ないために見落とされがちです。少数特徴はバイアスを引き起こし、不正確な結果につながる可能性があるため、モデルを学習する前にデータ内の少数特徴を識別し、考慮することが重要です。オーバーサンプリングやアンダーサンプリングなどのテクニックを使用することで、データセットのバランスをとり、少数特徴が無視されないようにすることができます。さらに特徴選択などのデータ前処理技術も、データ中の少数派の特徴を識別し、考慮するのに役立ちます。
SMOTE(Synthetic Minority Oversampling Technique)は、データセット内の少数特徴の問題に対処するために使用されるML技術です。これは、データセット中の少数特徴に類似した合成データ点を作成することで機能します。これにより、モデルは少数特徴からより良く学習することができ、より正確なモデルが得られます。SMOTEはデータセットに少数派の特徴が少ない場合に特に有効で、データセットのバランスをとり、これらの特徴が無視されないようにするのに役立ちます。
データサイエンティストのJoe Cincottaがfxguideに説明したように、「SMOTEはクラスタリングを使って、十分に表現されていないサンプルの近辺の値を近似します」これは単純な数値には有効です。 複雑な画像データセットの場合は、生成モデルの方がより望まれるものに近いです。画像データセットで少数派の特徴を特定した場合、少数派の画像でのみ学習されたGANや拡散モデルの出力を使用することで、少数派のオーバーサンプリングを実行しようとすることができます。
ドロップアウト
ドロップアウトは、オーバーフィッティングを防ぐためにMLで使われるテクニックです。オーバーフィッティングは、モデルが訓練データにフィットしすぎて、未知のデータに汎化できない場合に発生します。ドロップアウトは、訓練中にニューラルネットワークからニューロンをランダムに「脱落」させることで機能しまうす。これによりネットワークは、未知のデータに適用できる、より一般的な特徴セットを学習するようになります。ドロップアウトはモデルの精度を向上させ、オーバーフィッティングの可能性を減らすのに役立ちます。
オーバーフィッティングは良いこともある
LAで開催されたSIGGRAPHで、Wētā FXチームは、パンドラの水棲生物メトカイナ一族のサンゴ礁の村の近くの海底に生息する生物のオーバーフィッティングについて語りました。

オーバーフィットは、特定のユースケースのための合成データを生成するために意図的に使用することができます。小さなデータセットにモデルをオーバーフィットさせることで、データ分布の複雑な詳細を捉えることができます。そして、コントロールされたバリエーションや摂動を導入することで、元のデータの特徴を維持した新しい合成例を作成することができます。このテクニックは実世界のデータが限られているが、モデルをより良く一般化したい場合に特に有効です。例えば、Wētā FXのオーバーフィッティングは、注意深くコントロールされ、目的を持って行われています。彼らの目標は、未知のデータに対してパフォーマンスの低いモデルを作成することではなく、学習データから複雑なディテールを捉えるモデルの能力を活用し、この知識を制御された方法で使用して、類似しているが独創的な水中植物や海藻を大量に生成することです。
MLアルゴリズムに世界を教えるために映画を作る。
NVIDIAの新しいマゼンタグリーンスクリーンアプローチは、今年のSIGGRAPHでも注目されました。この研究は、グリーンスクリーンをキーイングするための新しいアプローチとして、いくつかの一般紙で取り上げられました。しかし、これは、トレーニングデータとして使用するための非常に高品質なマットを生成する新しい方法であるという、主要なポイントを見逃していました。 前景の俳優のカラー画像と高品質のアルファチャンネルを同時に記録することにより(特別なカメラや手動のキーイング技術を必要としない)、非常に正確なマットを素早く作成する自動化された方法を提供します。
チームは、緑色の背景に俳優を録画し、赤と青の前景照明のみで彼らを照らす新しいアプローチを設定しました。これは、分離と最新のCMOSカメラの設計方法によって非常にうまく機能します。この構成では、緑色のチャンネルは、明るく均一な背景を背景にした俳優のシルエットを示し、俳優のアルファチャンネルの逆であるホールドアウトマットとして直接使用することができます。次に彼らはMLを使用して前景の緑チャンネルを復元するために、まったく別のAIを使用しますが、前景の再色付けにのみ使用します。そのために、白色照明で照らされた俳優のシーケンス例を用いて色付けモデルを学習させ、説得力のある前景の結果を得ています。真の問題は、再色付けにMLを使用することではなく、マットの品質です。
彼らの技術で出力された高品質のアルファチャンネルデータは、将来のMLマッティング研究で作られる新世代の自然画像マッティングアルゴリズムのための、格段に優れたトレーニングデータセットを提供します。

そして、それは拡大する一方です
特にジェネレイティブ・モデルの急速な発展により、合成データ生成は今後ますます拡大していくでしょう。