VFXにおけるAI、機械学習に関する記事が公開されていたのでメモしておきます。 https://www.fxguide.com/fxfeatured/the-art-and-craft-of-training-data- […]
参考資料
トレーニングデータの芸術と技術

![]()
VFXにおけるAI、機械学習に関する記事が公開されていたのでメモしておきます。 https://www.fxguide.com/fxfeatured/the-art-and-craft-of-training-data- […]

Pixarの新作「マイ・エレメント」のカーブを使用したキャラクターリギングのデモ映像が公開されています。カーブを使用したリグは去年論文を公開していましたが、実際に制作で使用されてるグラフィカルなコントローラーを見ることが […]

2D動画から 3Dシーンを再構築する「NVIDIA Neuralangelo」の映像が公開されています。 現在よく見かけるマルチビュー ステレオ アプローチ(複数の写真から3D形状を復元するやつ)に代わるAI ベースの研 […]
アバター 2 で使用された新しいフェイシャル パイプラインの記事が公開されています。 https://www.fxguide.com/fxfeatured/exclusive-joe-letteri-discusses- […]

ピクサーのカーブを使用したキャラクター制御の新しいアプローチの論文が公開されています。 https://graphics.pixar.com/library/ProfileMover/ 概要 コンピュータアニメーションは […]
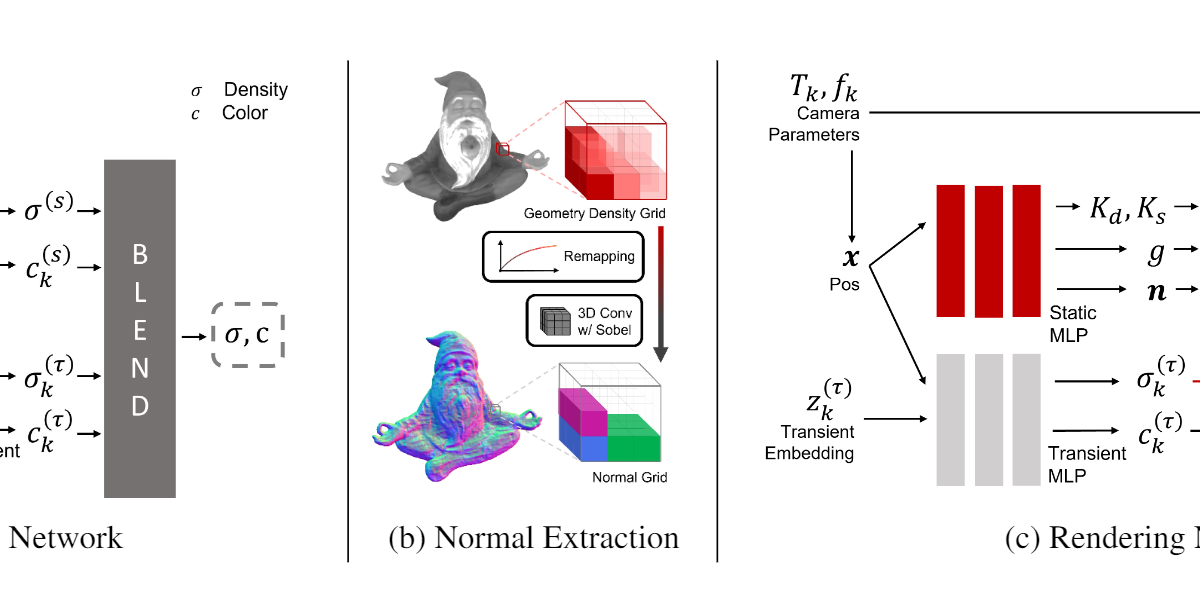
カメラ、照明、背景が異なるオンライン画像から、3Dオブジェクトを作成する技術が発表されています。 https://formyfamily.github.io/NeROIC/ 概要 カメラ、照明、背景が異なる写真から任意 […]
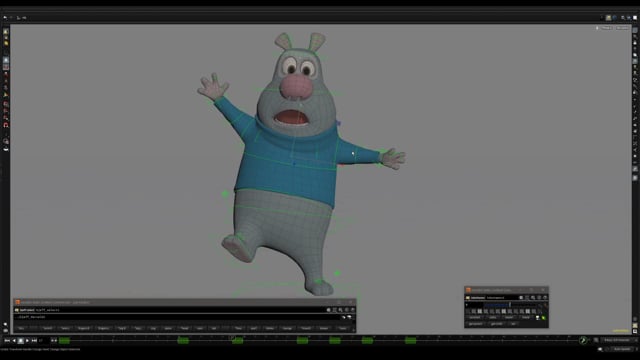
Houdiniで作成したリグだそうです。珍しい。 Houdiniで作成したリグテンプレート。ボディはオブジェクトベースのボーンを使用しており、フェイスはワイヤーデフォーマー+シェイプです。

WebGLを使用したCGに使用される技術をまとめたプレゼン資料のようです。WebGLを使用したインタラクティブな内容がわかりやすくて面白いです。 http://acko.net/files/fullfrontal/ful […]

2Dイラストから3Dモデルを自動生成する実験をしてる人を見かけました。面白いですね。 2Dイラストから3Dモデルを自動生成する実験の続きです。 目のランドマークを増やし、素体の変更を試してみました。今回は @YAN3dc […]

地味だけどベクタースカルプトが便利そう。

角煮めくるシミュレーションはいつ見ても凄い。

ライオンのリアルさ凄すぎ。 スカーを作るためにチームはまずコンセプトアートを参照することから始めました。 キャラクターのデザイン。モデリングチームは、このアートとライオンの写真を使用して、スカーの形と形を見つけました。モ […]
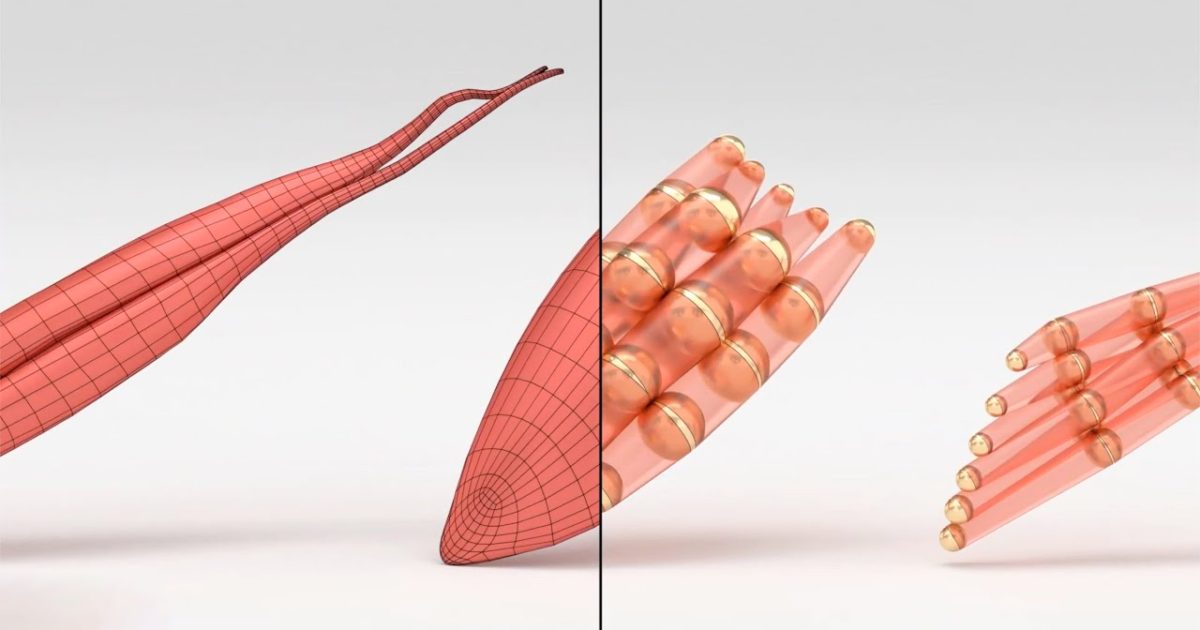
VIPER -- 体積不変位置弾性ロッド https://github.com/vcg-uvic/viper

ライティングに関する解説ビデオ。とても勉強になります。ユーモアがあって楽しく見られるのもいいですね。

Maxで筋肉までリギングされてるのは珍しい気がする。