静止画像からキャラクターの動画を安定して生成することを目的とした技術論文が公開されています。
https://humanaigc.github.io/animate-anyone/
概要
キャラクタアニメーションは、静止画像から駆動信号によってキャラクタ動画を生成することを目的としている。現在、映像生成の研究においては、そのロバストな生成能力から拡散モデルが主流となっている。しかし、画像から動画への変換、特にキャラクタアニメーションにおいては、キャラクタの詳細な情報との時間的な整合性を保つことが困難であるという課題が残されている。本論文では、拡散モデルの力を活用し、キャラクターアニメーションに合わせた新しいフレームワークを提案する。参照画像からの複雑な外観特徴の一貫性を維持するために、空間的な注意を介して詳細な特徴を統合するReferenceNetを設計する。制御性と連続性を確保するために、キャラクタの動きを指示する効率的なポーズガイダーを導入し、ビデオフレーム間のスムーズなフレーム間遷移を確保するための効果的な時間モデリングアプローチを採用する。学習データを拡張することで、本手法は任意のキャラクタをアニメーションさせることができ、他の画像からビデオへの手法と比較して、キャラクタアニメーションにおいて優れた結果をもたらす。さらに、ファッションビデオと人間のダンス合成のベンチマークで本手法を評価し、最先端の結果を得た。
メソッド
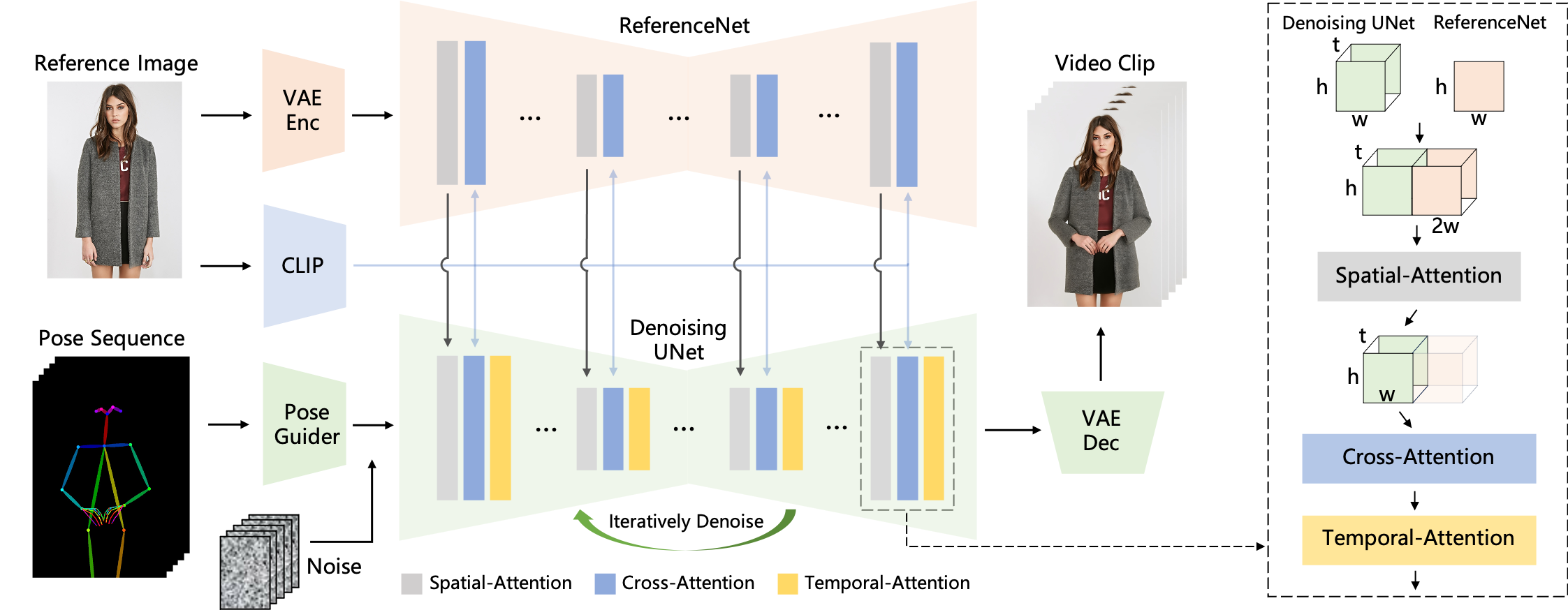
本手法の概要。ポーズシーケンスは最初にPose Guiderを用いてエンコードされ、マルチフレームノイズと融合される。デノイジングUNetの計算ブロックは、右の破線枠に示すように、空間的注意(Spatial-Attention)、交差的注意(Cross-Attention)、時間的注意(Temporal-Attention)から構成される。参照画像の統合には2つの側面がある。第一に、詳細な特徴がReferenceNetを通じて抽出され、Spatial-Attentionに利用される。次に、CLIP画像エンコーダを通して意味的特徴が抽出され、Cross-Attentionに利用される。Temporal-Attentionは時間次元で動作する。最後に、VAEデコーダが結果をビデオクリップにデコードする。
さまざまなキャラクターのアニメーション
比較
ファッションビデオ合成
ファッションビデオ合成は、ドライビングポーズシーケンスを用いて、ファッション写真をリアルなアニメーションビデオに変換することを目的としている。実験はUBCファッションビデオデータセットと同じトレーニングデータで行われる。
ヒューマン・ダンス・ジェネレーション
Human Dance Generationは、実世界のダンスシナリオにおける画像のアニメーションに焦点を当てている。TikTokデータセットと同じトレーニングデータで実験を行った。