アバター 2 で使用された新しいフェイシャル パイプラインの記事が公開されています。
Wētā FXは、まったく新しいフェイス・パイプラインを開発しました。この画期的な新アプローチを最初に開発したのは2019年だが、同社は『Avatar: The Way of Water』の公開に合わせて、韓国で開催されたSIGGRAPH ASIAで新しいアプローチを公開したばかりです。この徹底討論ではWētā FX Snr.に直接話を聞いている。VFXスーパーバイザーのJoe Letteri氏と、テクニカルペーパーの他の著者の一人であるKaran Singh氏に、新しいアプローチを開発する決断をした理由について、直接話を聞きました。
背景
フェイシャルアニメーションの新しいシステムは、FACSパペットから解剖学的ベースとしての筋繊維曲線に移行することに基づいています。この新しいアプローチは、Anatomically Plausible Facial SystemまたはAPFSと呼ばれ、アニメーター中心で、解剖学的な発想から生まれた、顔のモデリング、アニメーション、再ターゲッティング転送のためのシステムです。

新システムは、Wētā FXが『ゴラム』以来一貫して使用してきた、受賞歴のあるFACSパイプラインに代わるものです。映画『アリータ:バトル・エンジェル』(2019年)のためにR&D FACSアプローチを極めて強く押し出したLetteri氏は、FACSベースのパペットシステムには、顔の筋肉の分離、カバー、線形組み合わせ使用、広域冗長性などの大きな問題が多すぎるだけだと判断しました。
例えばFACSは筋肉主導の表情を表す顔のポーズのセットをマッピングしますが、適切なフェイシャルアニメーションを得るために、FACSパペットリグは、アニメーターが信じられるパフォーマンスを達成できるように、900ものFACS形状をリグに追加することになってしまうかもしれません。FACSが「間違っている」のではなく、タイムベースのフェイシャルアニメーションのために設計されたシステムではないのです。FACSは音声を中心に構築されたものではなく、むしろ孤立した感情表現を中心に構築されたものです。
「私たちは、アーティストが顔の動きを直接コントロールできるシステムが必要だったのです」とLetteri氏は語る。「FACSはあくまで感情ベースのシステムであり、表情をコード化するものです。FACSには対話はありませんし、私たちがやっていることはほとんど対話です。FACSは正確な孤立した表情を表すかもしれませんが、ポーズ間の移行方法に関する情報はありません。結局、一種の推測をしなければなりません。移行を直感するようなもので、それは素晴らしいことですが、維持するのは困難です」とLetteri氏は説明しています。FACSシステムは、状態から状態へ移行するときに、基本的に顔全体に直線的に状態変化が起こるので、非常に "rubbery "なのです。
Letteri氏と彼のチームは、フェイスパイプライン全体をゼロからやり直すことにしました。「私はこの問題を見て、こう思いました。これはもうやりたくない。これは難しすぎる。もっといい方法があるはずだと。顔の筋肉がどのように配置され、どのようにつながっているのか、もう一度見直してみました。そして、その結合をマップ化すれば、顔を表現する高次元空間の基礎ができることに気づいたのです」。
チームは、表情が作られ、筋肉が活性化すると、他の筋肉が連動して活性化したり、筋肉が受動的に引っ張られたりすることに着目しました。"筋肉が神経ネットワークによく似た一種のネットワークで相互接続しているため "と、Letteri氏は推論しています。
「そこで私は、筋肉を直接ベースとする神経回路網を作ればいいのではないかと考えたのです。つまり、多くのディープラーニングは、問題に数字を投げかけて、たくさんのデータを与えれば、相関関係を割り出してくれようとするものなのです。でも、私たちはすでに相関関係を知っているのだから、それを基礎としてコード化すればいいのでは?数学の世界に入り込めば、それは大きな微分積分の連鎖になります。基本的な微積分です」。
そしてチームは、アニメーターが顎、目、筋肉のどのような組み合わせでも表現できるようなシステムを構築することを目指しました。「ベースとして、例えばシガニー・ウィーバーの顔を見て、"筋肉 "が何をしているかを解くようにシステムを訓練し、それを別のネットワークでキャラクターに転送できるのは素晴らしいことです」。
さらに、筋肉カーブにより、アニメーターは顔の筋肉ごとに直接コントロールできるようになりました。ただし、筋肉曲線は、皮膚の下にある実際の筋肉と1対1で一致するように設計されているわけではないことを指摘する必要があります。筋肉曲線は、アニメーターがコントロールできる方法で、かつ、非常に高い忠実度でキャプチャされたパフォーマンスである顔の動きと一致するように、顔を解決するように設計されています。
APFS
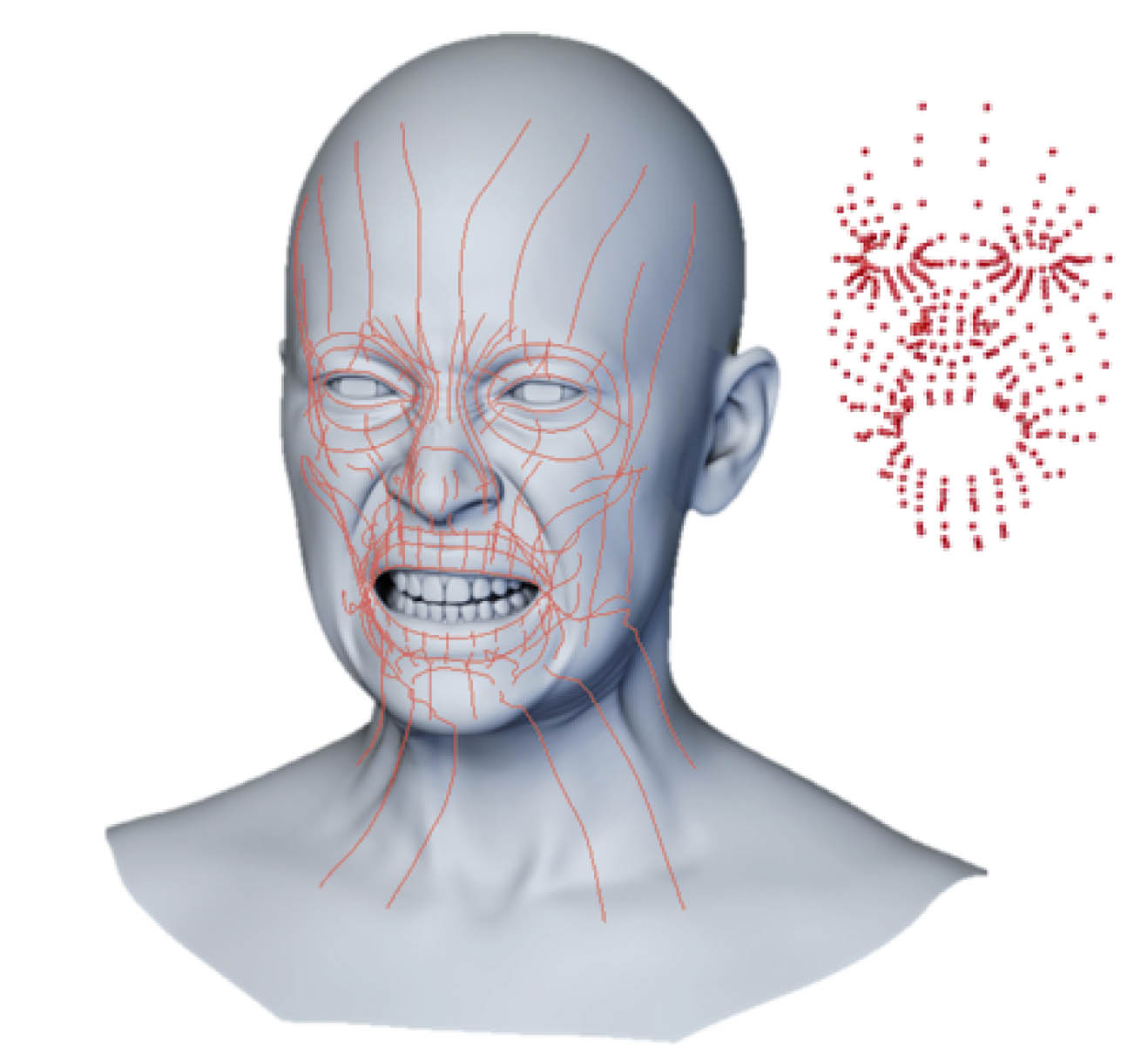
新しいAPFSは、178本の筋繊維の曲線、つまり「歪み」の曲線に基づいています。これらの筋繊維曲線が収縮・弛緩することで、きめ細かく忠実な人間の顔の表情が得られます。エンドツーエンドのシステムは、インワードアウト(顔が筋繊維曲線によって駆動される)とアウトサイドイン(アニメーターが顔の表面から顔を「正しく」ドラッグして動かすことができる)の両方が可能です。
このシステムは、人間の筋肉を1対1でマッピングしているわけではありません。上唇の湾曲など、顔のいくつかの側面は、実際には顎や下顔面の筋肉によって駆動されている結果だからです。むしろ、このシステムは178の曲線からなる配列であり、解剖学的なインスピレーションに基づく一連の制御を可能にしますが、肉/筋肉の直接的なエミュレーションやシミュレーションではありません。
さらに、FACSの人形はFACSの表情の直線的な組み合わせで作られており、回転は含まれていません。眼球を中心とした回転成分を自然に含む正しいまぶたのアニメーションを得るには、一連の中間的なFACS形状を追加する必要があります。
まぶたの例
各筋肉または歪み曲線には、関連する歪み値があります。筋肉のカーブは実際にはねじれませんが、ひずみ値はカーブに沿って、その局所空間における収縮または拡張を提供します。ある意味これは長さの変化率です。実際の曲線のひずみ数値は単位がなく、これは異なる文字に転送する際に役立ちます。ひずみ値は単独で機能するというより、セットの一部として機能します。
例えば、まぶたの瞬きには、まつ毛のラインに沿った筋カーブ(水平方向)と、直交方向(目の周りの上下方向)の両方が存在する。この場合、水平方向の曲線は眼球の上を回転しているため、実際のひずみ値はあまり変化しませんが、垂直方向の曲線はひずみ値が劇的に変化しています。
しかし、最も重要なのは、垂直カーブが筋肉のカーブ形状に沿ってスケールすることで、これは眼球のカーブと一致します。開いているブレンドシェイプと閉じているブレンドシェイプの間の同様の遷移は、(眼球の周りで曲がることなく)閉じてから開くまで直線的に移動するだけです。
Mayaでは、ブレンドシェイプをチェーンして、眼球の周りでカーブするまぶたをシミュレートすることができますが、これもブレンドシェイプの数を増やしてしまうことになります。
FACSソリューションは、フェイシャルリグの標準化を可能にしましたが、FACSは顔の表情の自発的で区別できるスナップショットをキャプチャするために心理学の観点から設計されており、コンピュータアニメーションに適用すると明らかに限界があります。
FACSのアクションユニット(AU)は、複数の表情筋の動作を組み合わせるAUや表情筋が全く関与しないAUのように、望ましい表情を得るために引き算で組み合わせる必要がある)、定位とアニメーション制御(冗長、動作が反対、強く関連、または相互に排他的なAUがあり得る)、AUはヒンジでつながれた顎と人間の唇の複雑な形状変形にしか近似しないなどです。
新システムの構築には、機械学習が用いられました。80の動的モーションクリップから6000〜8000のスキャン(フレーム)を使用しました。約60%がFACSの形状ポーズ、40%がスピーチモーションです。各俳優の演技は、検証されたグランドトゥルース表現から340のマーカーを基に解かれました。APFSパイプラインは時間情報をエンコードせず、これはパフォーマンスキャプチャの解答そのものから得られるものである。アニメーションは俳優の動きと表情を本質的に追跡します。

あご
新しいシステムでは顎と唇が特に注目されています。「システムを構築しているときに気づいたことのひとつに、顔の状態をコントロールする主要な手段が顎であるということがあります」とLetteri氏は語ります。
「特に対話の場合、顎は常に動いています。 さらに、人の顎は盾の軌跡の形でしか動かないので、顎が状態を動かす主役です」とLetteri氏は説明します。下顎骨は顎関節を介して頭蓋骨に固定され、靭帯と筋肉で支えられている。そのため、顎の可動域は、顎の想定される点の集合をトレースすることでマッピングすることができます。このような点の集合を人物のあらゆる台詞や表情に対応させると、盾のような形状になります。これを「ポッセルトの運動包絡線」または「ポッセルトシールド」と呼びます。
「このシールドは、ドライバー自身の制約システムに組み込まれています。"筋肉はその上で解かれます" というのも、チームがどの俳優を解析するときでも、デジタル頭蓋骨を俳優に適合させるフォレンジックフィットを行うからです。次に、顎の可動域を把握し、HMCのステレオカメラを使って深度情報を抽出します。そして、PCAを実行して、コヒーレントなメッシュが得られるように、最適なフィッティングを試みます。そして、そのメッシュに顎と頭蓋骨をフィットさせるのです」。
パフォーマンス・キャプチャーの場合、人間の動作にはすでに動きや可動域が含まれています。しかし、手作業でアニメーションを作成する場合は、Jawコントローラにシールドの制約が組み込まれます。アニメーションの検証は、その俳優の各カメラから取り込んだ画像に対して、歯並びを観察することで行いました。
同様に、俳優の目も非常に慎重に扱われています。システムの目のモデルは、アクターの強膜、角膜、虹彩にマッチしています。虹彩モデルが、各カメラから取り込まれた画像に見える辺縁リングと瞳孔に一致するように、眼球を回転させることによって、各フレームで視線方向を調整するのです。眼球はレンズ効果や屈折を示すため、追跡するのが非常に難しいのです。複数のカメラアングルを使用して、アライメントを確認し、角膜によって屈折する光を考慮します。 正面からの小さな目の膨らみも、それぞれの目の回転に適用して、キャラクターの目のリアリズムを高めています。

四面体(テト)フェイシャルボリューム
曲線筋は単なる線であるため、歪んだ筋肉とデジタルキャラクターの皮膚との間にリンクが必要です。曲線は筋肉の動作の線を捉えているのですが、実際の顔の中にも埋め込まれているのです。
ここでは、キャラクタの静止ポーズにおける顔の軟組織を離散化した四面体ボリュームを使用したボリューム表現によって、顔をシミュレートしています。テトのボリュームソリューションは、皮膚と、頭蓋骨と顎の骨の間に位置します。テトは概念的または数学的な「ゼリー」を形成しています。このテトボリュームに対して、皮膚の頂点と頭蓋骨を位置拘束として、スキャンシーケンス全体に対してパッシブな準静的シミュレーションを実行します。有限要素解析(FEA)を用いて,135,000 個のテト(複数の位置拘束,スライド拘束,衝突拘束を持つ)の「パッシブシミュレーション」をフレーム単位で行い,解剖学的にもっともらしい肉の挙動を生成しています。ここで生成される「肉付けマスク」は、学習段階での役割しか持ちません。

実際のマッスルリボンとマッスルカーブの比較
顔の筋肉はリボン状の筋肉であることが多いのですが、APFSのカーブには幅がありません。そのため、必要な部分にカーブを追加しています。筋肉カーブはアクティブマッスルシムではありません。「実際、アニメーターはそれを望んでいません。彼らはフレーム間の制御を望んでいます。彼らは運動学的な変形制御を望んでいるのです。シミュレーションの設定をした後、再生を押して、実際のアクティブなシミュレーションが引き継がれるのを見たくはないのです」そのため、チームは曲線表現を選択し、「曲線にこだわることにしたのです」と彼は付け加えます。「私たちは、できる限り最小限の、絶対的なパラメトリック表現を採用したのです」。

Karan Singh氏はCOVIDの直前、2020年にVictoria Universityに客員研究員として滞在していたため、チームに参加しました。彼は、自分が主席研究員ではないことを最初に言いますが、SIGGRAPH ASIA Submissionにプロセスを書き上げる上で大きな役割を果たし、ライブプレゼンテーションを行ったByungkuk Choi Haekwang EomとBenjamin Mouscadetと共に韓国でプレゼンテーションに参加したのです。
各エンジニアは、大規模なエンドツーエンドのソリューションの一部として、特定の焦点とモジュールを持っていました。この論文には、Joe LetteriとKaran Singhを含む12人の著者がいます。
Singh氏は、以前AutodeskのMayaでオリジナルのブレンドシェイプコードを書いた経験があり、FACSパペットで使用される詳細なコードに精通しています。Singh氏は新しいパイプラインの内部で機械学習(ML)オートエンコーダ(AE)を巧みに利用し、表現をオンモデルに保っていることを指摘します。
MLはWētāのようなパイプラインを変革しているが、多くの人がまだ十分に理解していない方法です。 VAEとそのディープフェイク・フェイススワップツールとしての使用については多く書かれていますが、APFSチームはここで、AEなどのMLツールが、最終的なピクセルに明示的に使用されない一方で、重要なタスクを支援するために複雑なパイプラインの内部で使用されていることを紹介しています。
このシステムは従来のFACSブレンドシェイプを使用して簡単にモデルから外れることができますが、ソリューション空間はAEによって制限されています。「初期テストや個々のキャラクターのトレーニングデータを定義するとき、そのキャラクターの範囲を設定しているのです」とSingh氏は説明します。「オートエンコーダーはそれを一種のエンコードとして扱うので、エンコードするのは一般的な設定だけではありません。つまり、一般的な設定をエンコードしているのではなく、非常に特殊なパフォーマンスをエンコードしているのです」。パイプラインの構築方法におけるAEは、ターゲットとモデル通りの顔を維持します。
ポーズライブラリの転送
アニメーターは当然ながらポーズライブラリを持つことに慣れています。しかし、ポーズは動きを強制したり、符号化したりするものではないので、組み合わせによって簡単にモデルから外れてしまうことがあります。そこで、アニメーターが使いやすいように、ひずみベースのモーションライブラリが作られました。
このアウトサイドインのアプローチは、カーブへのインバースマッピングを提供します。しかし、システムの構築方法とオートエンコーダの使用により、アニメーターが誤ってモデルから外れることはありません。筋肉の伸縮は直感的に理解できても、歪みベクトルで顔の表情を動かすのは一筋縄ではいきません。そこで、AE(オートエンコーダ)を導入し、ひずみベクトルが顔アニメーションの妥当な範囲に収まるように制約をかけることで、アーティストを支援します。
このモデル上の解空間を表情多様体と呼びます。ここで何が妥当かを定義するのはアニメーターであり,アニメーターは意図的にモデルから外れることを選択できますが,表情多様体は,複数の表情とそれに対応するひずみベクトルまたは設定の範囲から厳選されたサンプリングを用いて,アニメーターのために推定されます。

ディープシェイプ
アバター:ザ・ウェイ・オブ・ウォーターでは、多くの俳優が水中でパフォーマンスをキャプチャしていましたが、顔のアニメーションのほとんどは、乾いた土地での二次キャプチャに基づいており、それをメインのパフォーマンスキャプチャにブレンドしていました。顔のパフォーマンスキャプチャを行う際、アクターはステレオヘッドリグ(HMC)を装着しましたが、新しい技術のおかげで、アバター1のオリジナルHMCよりも重くありませんでした。
HMCカメラの固定ステレオ配置のおかげで、WētāのチームはDeep Shapeという強力な新しいビジュアライゼーションツールを開発しました。このステレオ画像を使って、俳優の実際の演技を3D点群風に再現し、どの角度からも見ることができるようにしました。画像はモノクロでポリゴン化されていませんが、実際の演技を高度に再現しています。
この新しいビジュアライゼーションにより、アニメーターは、実際のキャプチャーカメラの生の出力のような広角の歪みや奇妙な視野角なしに、顔からわずか数フィートの距離で撮影されたかのように、仮想の目撃者カメラを持つことができるようになるのです。
このような3D深度再構築ビューにより、唇や顎の伸展を観察し、後で完全に制御可能で再構築されたアニメーションが生ビューに忠実であるかどうかを判断する、より強力な方法を提供します。このように著しく便利な表示装置であるため、これまで誰も実装していなかったことが不思議なくらいですが、私たちの知る限り、Wētā FXはDeep Shape可視化オプションを正確に実現した最初のチームです。このツールは、APFSエミュレーションを比較・判断するための顔のグランドトゥルースの重要な参考ツールになります。 これは、新しいエンド・トゥ・エンドのAPFSベースのソリューションのもう一つの革新です。

エイジング
現在では一般的な手法として、俳優の顔の表情に合わせたデジタルダブルを非常に忠実にアニメーション化し、そのアニメーションをキャラクターモデルに転送しています。Wētāは、アニメーション転送時に俳優とキャラクターの顔の一致を最大化するために、対応する俳優の基本的な筋肉の挙動を共有するように、戦略的にキャラクターのトレーニングプロセスを設計しています。
3Dキャラクターの顔モデルは、最終的にそれぞれの俳優と同じ、共有された歪みオートエンコーダーを持つことになります。皮膚は正確にマッピングされ、目と顎の領域はユーザー定義のウェイトマップを使って別々に処理され、顔の重要なパーツをより正確に表現できるようになります。当然ながらナヴィのユニークな形状を考慮し、チームはアクターの顎のリグをキャラクターに慎重に適合させ、歯のトポグラフィーと頭蓋骨の解剖学の偏差を補償するためにそれを使用する必要があります。

カーブマッスルシステムは、首の部分までカーブが伸びており、ボディパフォーマンスキャプチャとの統合をより良くしています。耳については、まったく別のコントロールが用意されています。
「今回、わざわざキャプチャーしようとしなかったのは、耳は一種の二次的効果だからです」とLetteri氏は言います。「ナヴィの耳は表情豊かですが、人間には全くありません。ですから、あれはあくまで別のアニメーション制御システムなのです」

この映画では、当然ナヴィへの再ターゲットが多数ありますが、重要なのは、2つの重要な脱老化の再ターゲットがあることです。俳優のシガニー・ウィーバーとスティーブン・ラングは、ともに若いキャラクターに再ターゲットされています。キリと若いクオリッチです。
顔の筋肉の緩みや老化をシミュレートするために歪みの値を変えることを検討する人もいるかもしれませんが、Letteri氏は、リターゲティングがそれを完全に補うので、歪みの値を「緩和」したり伸ばしたりする必要がなかったと指摘しています。 「そうすることも考えましたが、それでは不確実性が増してしまいます」とLetteri氏。「そこで、まずはリターゲティングで試してみようと考えました。そして、それを実行したのです。そして、うまくいくようになりました。
