Houdini用のプロシージャルアナトミーを生成するツールだそうです。Houdini で KineFX 互換の筋肉と皮膚のシミュレーション リグを作成できます。l現在オープンベータ中で8月6日まで無料で使用 […]
参考資料
Procedural Anatomy for Houdini

![]()
Houdini用のプロシージャルアナトミーを生成するツールだそうです。Houdini で KineFX 互換の筋肉と皮膚のシミュレーション リグを作成できます。l現在オープンベータ中で8月6日まで無料で使用 […]

Maya用のモジュラーリギングプラグイン「Mansur-Rig」が無料化されたようです。 https://mansur-rig.com/ 正しくリグして、すばやくアニメート! Maya用の最も先進的なモジュ […]

Houdini 20.5 のSneak Peekが公開されています。毎回凄そうに見える。

ポリゴン・ピクチュアズがリグ・アニメーション フレームワーク「eST」をリリースしました。 概要見るとモジュラーリグとツールみたいですね。ログインしないとドキュメントが見れないようです。 https://www.ppi. […]

Houdini 20 のSneak Peekが公開されています。デモの範囲が多岐にわたってて、ゲームエンジンのデモのようです。

Pixarの新作「マイ・エレメント」のカーブを使用したキャラクターリギングのデモ映像が公開されています。カーブを使用したリグは去年論文を公開していましたが、実際に制作で使用されてるグラフィカルなコントローラーを見ることが […]

modoでプロシージャルな鎖(リンクチェーン)を作る方法について書いてみます。鎖はアクセサリーや駐車場スタンドなど身近でよく使われているので、CGで作る機会の多い定番の題材です。 modoには鎖を表現する方法がいくつかあ […]
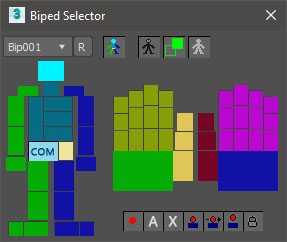
3ds Max用のCompact Biped Selector スクリプトが公開されています。 https://www.scriptspot.com/3ds-max/scripts/compact-biped-selec […]

Maya用の無料のノード リギング システム「Baguette」が公開されています。 https://github.com/nimsb/Baguette/releases Framestoreのリギングスーパーバイザーで […]

複数のMeshOpsやChannel Modifiersが含まれるmodo用のユーティリティ集「Polly for MODO」がリリースされました。価格は$15です。 https://stevehill3d.gumroa […]
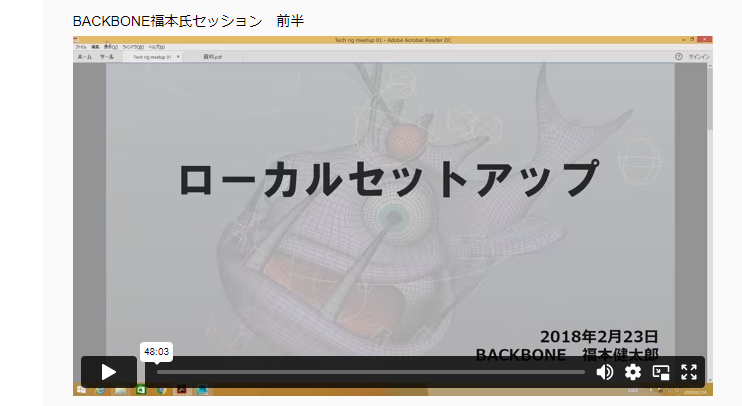
2018年2月24日(土曜)に開催された「Rigging help me !」セミナームービーが誰でも視聴可能になったそうです。Maya界隈でよく使われるローカルセットアップについての映像です。 https://supp […]
アバター 2 で使用された新しいフェイシャル パイプラインの記事が公開されています。 https://www.fxguide.com/fxfeatured/exclusive-joe-letteri-discusses- […]

ピクサーのカーブを使用したキャラクター制御の新しいアプローチの論文が公開されています。 https://graphics.pixar.com/library/ProfileMover/ 概要 コンピュータアニメーションは […]

modoのOCIO カラーマネジメントを使用してmodoで ACES を使用する方法と、レンダリングを Photoshop に取り込む方法の簡単なチュートリアルです。 modo 14.1 でカラーマネジメン […]
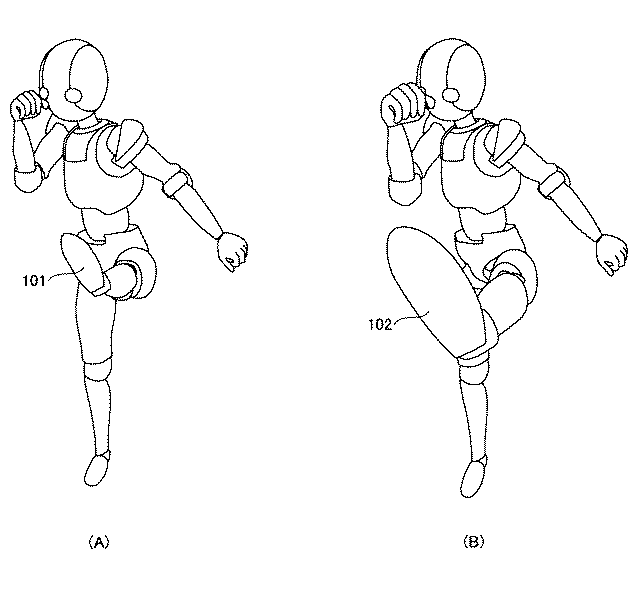
CLIP STUDIO PAINTの漫画パースが特許取得してると話題なってたのでメモ。ボーン単位で変形してるっぽい? https://astamuse.com/ja/published/JP/No/2014149748 […]