Microsoft ResearchがAIを使用して3Dレンダリングを実現する「RenderFormer」を紹介しています。BlenderのCyclesを学習させたみたいですね。
レンダリング速度と品質が既存のレンダラーを越えたら、AIレンダラーに置き換わる未来が来るのかな。
RenderFormer:ニューラルネットワークが3Dレンダリングを再構築する仕組み
3Dレンダリング——三次元モデルを二次元画像に変換するプロセス——は、コンピュータグラフィックスの基盤技術であり、ゲーム、映画、仮想現実、建築ビジュアライゼーションなど幅広い分野で活用されている。従来、このプロセスはレイトレーシングやラスタライズといった物理ベースの手法に依存しており、これらは数学的公式と専門家が設計したモデルを通じて光の挙動をシミュレートする。
現在、AI、特にニューラルネットワークの進歩により、研究者たちはこれらの従来の手法を機械学習(ML)で置き換え始めている。この転換により、ニューラルレンダリングと呼ばれる新たな分野が生まれている。
ニューラルレンダリングは、深層学習と従来のグラフィックス技術を組み合わせることで、物理光学を明示的にモデル化することなく、複雑な光輸送をシミュレートすることを可能にする。この手法には大きな利点がある:手作業によるルールの設定が不要、エンドツーエンドのトレーニングが可能、特定のタスク向けに最適化できる。しかし、現在のニューラルレンダリング手法の多くは2D画像入力に依存し、生の3Dジオメトリや材質データのサポートに欠け、新たなシーンごとに再トレーニングが必要となる場合が多く、汎用性に制限がある。
RenderFormer: 汎用ニューラルレンダリングモデルに向けて
これらの制限を克服するため、Microsoft Researchの研究者らはRenderFormerを開発した。これは機械学習のみを用いて(従来のグラフィックス計算を必要とせずに)フル機能の3Dレンダリングをサポートするよう設計された新たなニューラルアーキテクチャである。RenderFormerは、レイトレーシングやラスタライズに依存することなく、任意の3Dシーンやグローバルイルミネーションのサポートを含む完全なグラフィックスレンダリングパイプラインをニューラルネットワークが学習できることを実証した初のモデルである。本研究はSIGGRAPH 2025で採択され、GitHubでオープンソース化されている。
アーキテクチャ概要
図1に示すように、RenderFormerは3Dシーン全体を三角形トークンで表現する。各トークンは空間位置、法線、拡散色・鏡面反射色・粗さなどの物理的材質特性を符号化する。照明も三角形トークンでモデル化され、放射値が強度を示す。
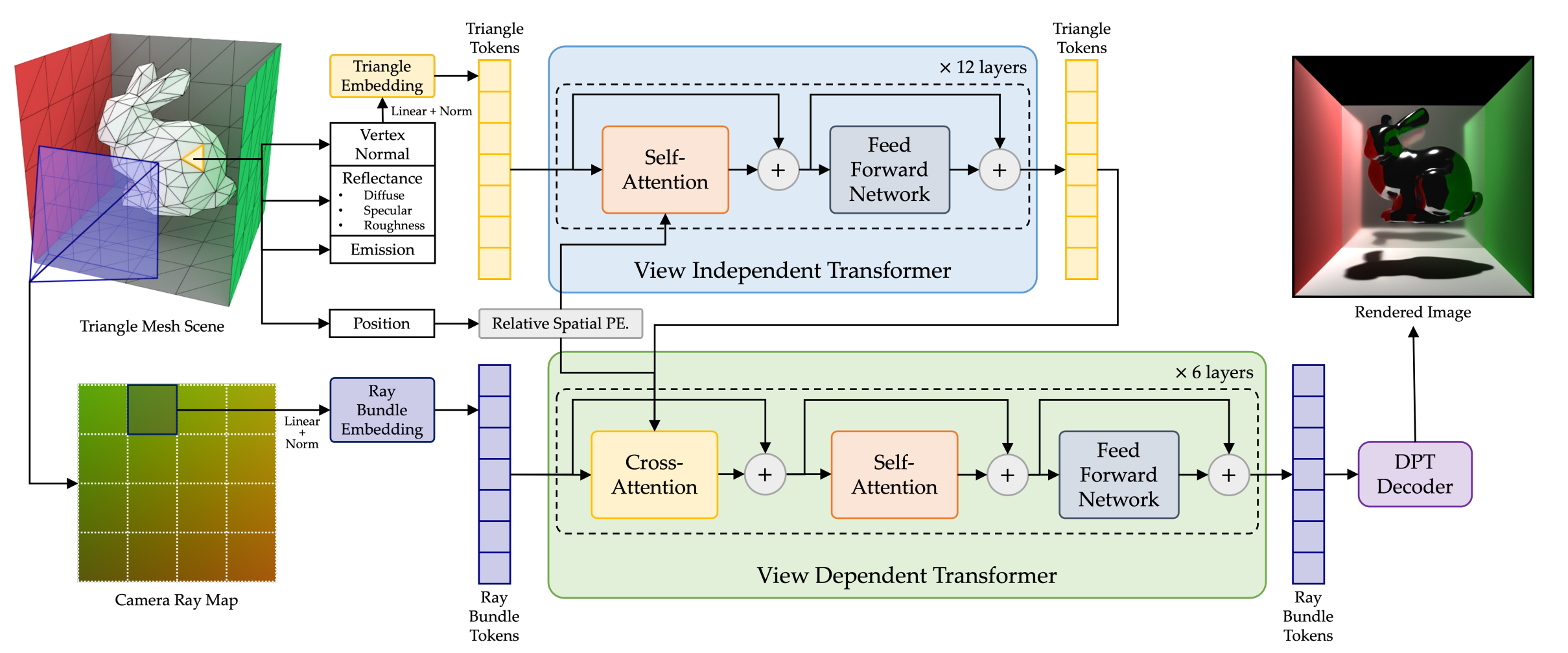
図1. RenderFormerのアーキテクチャ
視線方向を記述するため、モデルはレイマップから導出されたレイバンドルトークンを使用する。出力画像の各ピクセルはこれらのレイの一つに対応する。計算効率を向上させるため、ピクセルは矩形ブロックにグループ化され、ブロック内の全レイがまとめて処理される。
モデルは一連のトークンを出力し、これらが画像ピクセルに復号化されることで、レンダリング処理全体がニューラルネットワーク内で完結する。
ビュー独立効果とビュー依存効果のためのデュアルブランチ設計
RenderFormerアーキテクチャは、ビュー独立特徴用とビュー依存特徴用の2つのトランスフォーマーを中心に構築されています。
- ビュー独立トランスフォーマーは、三角形トークン間の自己注意を用いて、影や拡散光伝播など視点に関係しないシーン情報を捕捉します。
- ビュー依存トランスフォーマーは、三角形トークンとレイバンドルトークン間のクロスアテンションを通じて、可視性、反射、鏡面ハイライトなどの効果をモデル化します。
アンチエイリアシングやスクリーンスペース反射などの追加の画像空間効果は、レイバンドルトークン間の自己アテンションによって処理されます。
アーキテクチャの有効性を検証するため、チームはアブレーション研究と視覚的分析を実施し、レンダリングパイプラインにおける各コンポーネントの重要性を確認しました。
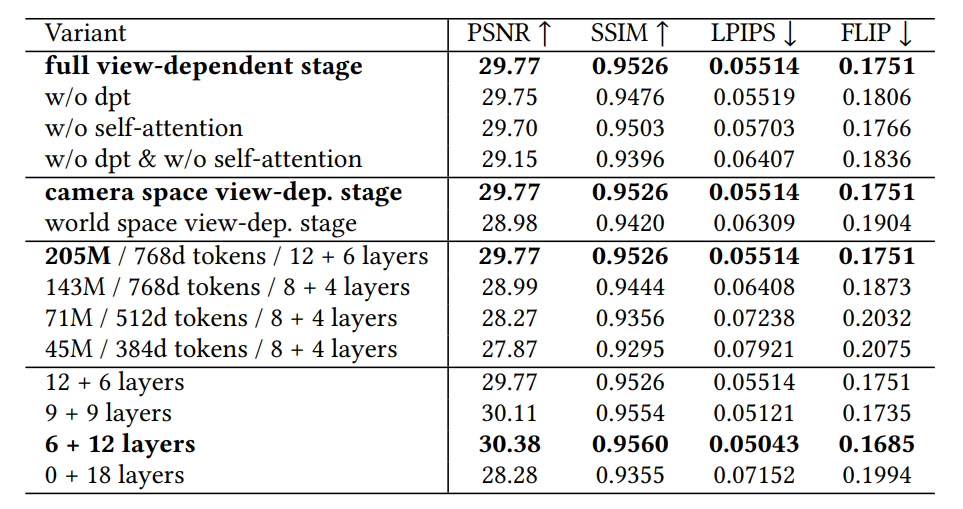
表1. 異なる構成要素と注意メカニズムが学習済みネットワークの最終性能に与える影響を分析したアブレーション研究
ビュー非依存トランスフォーマーの性能を検証するため、研究者らは拡散光のみのレンダリングを生成するデコーダーを訓練した。図2に示す結果から、本モデルが影やその他の間接照明効果を正確にシミュレートできることが実証された。

図2. 拡散照明と粗い影効果を含む、ビュー独立トランスフォーマーから直接デコードされたビュー独立レンダリング効果。
ビュー依存トランスフォーマーは、アテンション可視化を通じて評価された。例えば図3では、アテンションマップがティーポット上のピクセルが表面の三角形と近くの壁に注目していることを明らかにしており、鏡面反射の効果を捉えている。これらの可視化は、材質の変化が反射の鮮明さと強度に影響を与える様子も示している。

図3. 注意出力の可視化
トレーニング手法とデータセット設計
RenderFormerは、3Dモデリング、コンピュータビジョン、および関連分野の研究を推進するために設計された、80万点以上の注釈付き3Dオブジェクトを収集したObjaverseデータセットを用いてトレーニングされた。研究者らは4つのシーンテンプレートを設計し、それぞれに1~3個のランダムに選択されたオブジェクトと材質を配置した。シーンはBlenderのCyclesレンダラーを用いて、多様な照明条件とカメラ角度のもとでハイダイナミックレンジ(HDR)でレンダリングされた。
2億500万パラメータからなるベースモデルは、AdamWオプティマイザーを用いて2段階で訓練された:
- 256×256解像度、最大1,536三角形での50万ステップ
- 512×512解像度で最大4,096三角形を伴う100,000ステップ
本モデルは任意の三角形ベース入力をサポートし、複雑な実世界シーンへの汎化性能に優れる。図4に示す通り、影・拡散陰影・鏡面反射を正確に再現する。

図4. RenderFormerで生成された異なる3Dシーンのレンダリング結果
RenderFormerは、視点の変化やシーンの動的要素をモデル化する能力により、個々のフレームをレンダリングすることで連続した動画を生成することも可能です。
RenderFormerによる3Dアニメーションシーケンスのレンダリング
今後の展望:機会と課題
RenderFormerはニューラルレンダリングにおける重要な前進を示す。深層学習が従来のレンダリングパイプラインを再現し、将来的には置き換える可能性を実証しており、任意の3D入力と現実的なグローバルイルミネーションをサポートする——しかも手作業でコーディングされたグラフィックス計算を一切必要としない。
しかし、主要な課題は残されている。複雑なジオメトリ、高度なマテリアル、多様な照明条件を備えた大規模かつ複雑なシーンへの拡張には、さらなる研究が必要だ。それでも、トランスフォーマーベースのアーキテクチャは、動画生成、画像合成、ロボティクス、具現化されたAIを含む、より広範なAIシステムとの将来的な統合に向けた強固な基盤を提供する。
研究者らは、RenderFormerがグラフィックスとAIの両分野における将来のブレークスルーの基盤となり、ビジュアルコンピューティングと知能環境の新たな可能性を切り開くことを期待している。