今年3月末、クレジットカード会社からの要請によって表現規制されるこで話題になったDLsiteですが、4月3日にVisa / Mastercard / American Express の使用ができなくなりました。現在利用 […]
趣味
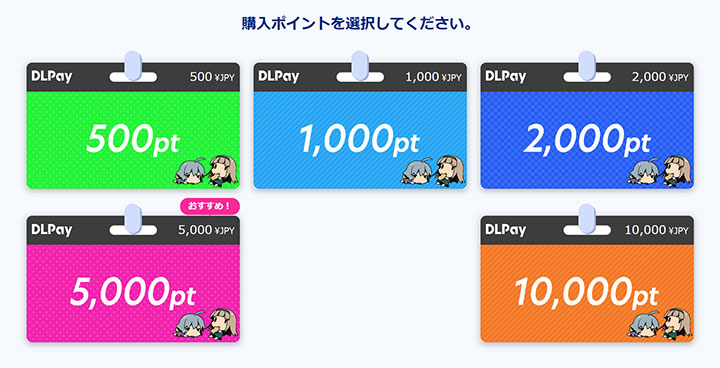
クレカの代わりに「DLsite ポイント」でゲーム買ってみた
![]()
今年3月末、クレジットカード会社からの要請によって表現規制されるこで話題になったDLsiteですが、4月3日にVisa / Mastercard / American Express の使用ができなくなりました。現在利用 […]

Amazon プライムで公開中のドラマ「Fallout (フォールアウト)」のメイキング記事が公開されています。撮影は 35 mm フィルムを使用し、ボルト内部の撮影ではLEDウォールを使用したセットが使用されており、 […]

生成AIのアップスケールをレンダリングの品質向上に利用するのはどうか?という興味深い記事が公開されています。 CGだと草のモデルをスキャッターするとパターン感が出てしまったり、テクスチャのリピート感が出てしまうことが多い […]

インディーズVFX短編映画『BYE-BYE』でAIツールをどのように使用したか記事が公開されています。AIツール使う映像スタジオのPR記事のような雰囲気ですが、メモしておきます。 https://www.cgchanne […]
3dsMaxのUSDに関する記事を見かけたのでメモ。 VFX アーティストでパイプラインの開発も手がけるChangsooさんのブログです。USDの解説はMayaを中心に書かれることが多いので、3dsMaxで書かれてるのは […]

「アニメーションのデモリールを制作するための10の秘訣」という記事が公開されています。リール作成の参考になりそうです。 https://www.cgchannel.com/2023/09/10-tips-for-craf […]

VFXにおけるAI、機械学習に関する記事が公開されていたのでメモしておきます。 https://www.fxguide.com/fxfeatured/the-art-and-craft-of-training-data- […]

先日Nvidiaが発表したNeuralangeloに関する記事が公開されています。 https://www.fxguide.com/quicktakes/neural-surface-reconstruction-fro […]

グランツーリスモにUSD採用のインタビューが公開されています。CEDEC 2022の方が詳細な話だった気がするけど、とりあえずメモ。 どうしてNVIDIA?と思ったらOmniverse関連なのか。 https://dev […]

3dsMax for V-RayのUIをQt化する話が紹介されていました。 3dsMaxのUIは長い間古いWin32ライブラリが使用されてきました。このため近代的なハード構成のPCでもUI描画が非常に遅くなっていました。 […]

全カットの背景にAI生成画像を使用した短編アニメ 「犬と少年」のインタビュー記事が公開されています。 背景にAIを使用していることを知ってて見たせいか、ぱっと見いい感じだけど背景の描き込みに目が引っぱられたりレイアウトが […]

『アバター:ウェイ・オブ・ウォーター』で使用されるハイフレームレート(HFR)+HDR+4K+3D上映に関連して、映画のフレームレートはどうやって決められたのか、という歴史が書かれた記事が公開されています。 映画は通常2 […]

ピクサーのアニメーターが、アーティストが見落としがちな10の微妙なエラーについて書いた記事が公開されています。 http://www.cgchannel.com/2022/03/10-subtle-mistakes-to […]
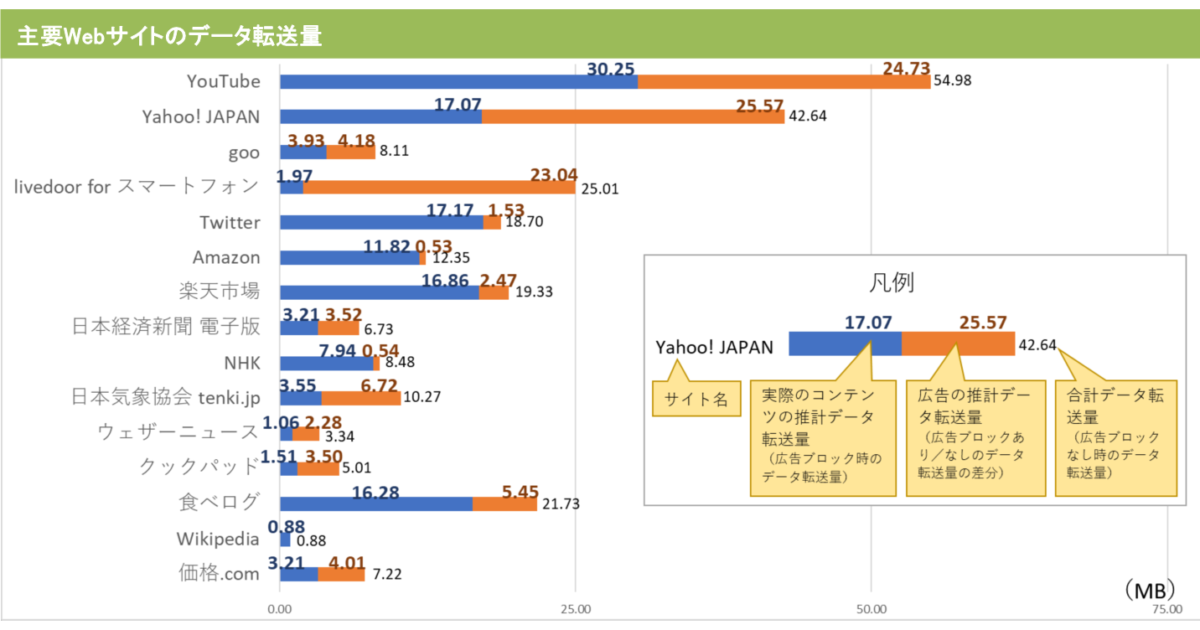
「スマホでのコンテンツ視聴に占める広告の比率調査」が公開されてたのでメモ。主要Webサイトのデータ転送量、平均4割は広告というデータになったそうです。 https://www.lab-kadokawa.com/relea […]
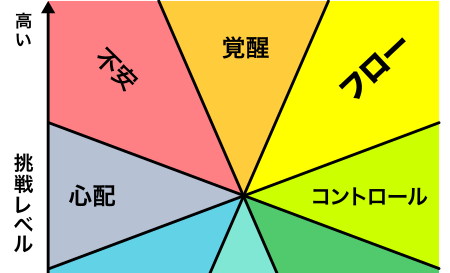
ゲームの面白さや体験を「フロー理論」を使用して改善することができるという記事。なかなか面白くて興味深い。https://note.mu/kaerusanu/n/nc80f9523bb8e フロー理論とは https:// […]